Agrupamiento de datos (estudio)
Contenidos de la página
Acerca de la agrupación de datos en Studio
Al crear un Tablero en Studio, puede especificar qué datos desea incluir en el Tablero. Puede limitar los datos de un informe agrupándolos, ordenándolos o filtración sus datos.
Hay una variedad de agrupaciones que puede utilizar para sus datos. Esta página explica cómo agrupar sus datos según estas diferentes agrupaciones.
Agrupar datos en un Widget
Consejo Q: No es posible agrupar datos en widgets de métricas o opinión .
Puede agrupar datos en tipos de widget compatibles. Para agrupar los datos en su widget:
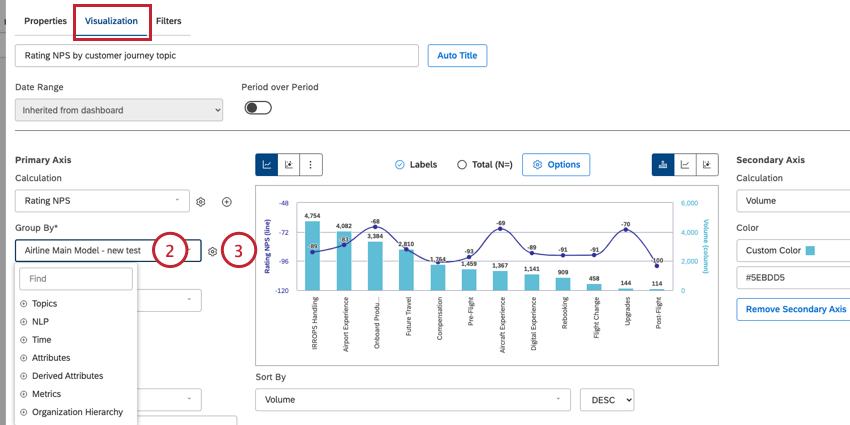
Consejo Q: Si se utiliza un mesa widget, entonces esta opción se llamará “Agrupaciones”. Si se utiliza un mapa de calor widget, entonces esta opción se llamará “Cajas”. Si se utiliza un red widget, entonces esta opción se llamará “Nodos”.
Temas
Seleccionando Temas Permite agrupar datos por categorías derivadas de los opinión de los clientes. Esto le proporcionará una descripción general de lo que están diciendo sus clientes.
Después de elegir su modelo de categoría, abra la configuración de agrupación para seleccionar qué temas se incluyen en el widget. Ver Personalización de agrupaciones de modelos de categorías Para más información.
Al agrupar datos por temas, puede optar por informar en diferentes niveles en su modelo de categorías. Para obtener una descripción general de alto nivel de lo que hablan sus clientes, agrupe los datos por Nivel 1 temas. Para monitorear temas más específicos en los opinión de los clientes, agrupe los datos por Nivel 2 temas o inferiores (dependiendo de su modelo). Para obtener el informe más granular en todos los niveles, agrupe los datos utilizando el Hoja opción, que le permite centrarse en hojas de temas o categorías que no tienen subcategorías.
PNL
Seleccionando PNL le permite agrupar datos según criterios creados automáticamente por el motor de procesamiento de lenguaje natural de XM Discover. Estos criterios se crean a partir de opinión no estructurados que procesa XM Discover. Hay varios subgrupos disponibles para que usted elija:
Palabras
El Palabras Las agrupaciones de PNL le permiten agrupar datos por palabras o tipos específicos de palabras mencionadas en los opinión de los clientes. Están disponibles las siguientes agrupaciones:
- Todas las palabras:Agrupar datos por palabras regulares. Esto le dará una idea de los términos más comunes que utilizan los clientes cuando hablan de su producto o servicio.
- Marca/organización CB:Agrupa datos por menciones de marca/organización .
- Compañía CB:Datos del grupo por menciones de empresas.
- Dirección de correo electrónico de CB:Agrupe datos por direcciones de correo electrónico mencionadas en los opinión.
- Emoticon CB:Agrupe datos por emojis y emoticones utilizados en los opinión.
- Evento CB:Agrupe los datos en torno a días festivos estándar (como Año Nuevo o Halloween), eventos de la vida (como bodas o graduaciones) y eventos culturales comunes (como el Super Bowl) mencionados en los opinión.
- Industria CB:Agrupar datos por industria relacionada.
- Persona CB:Agrupe los datos por nombres de las personas mencionadas en los opinión.
- Número de teléfono de CB:Agrupe los datos por números de teléfono mencionados en los opinión.
- Producto CB:Agrupar datos por menciones de productos.
- Blasfemias de CB:Agrupar datos por palabras profanas de un conjunto predeterminado.
Palabras asociadas
El Palabras asociadas La agrupación le permite agrupar datos por pares de palabras que se mencionan en relación entre sí en los opinión de los clientes. Esto le permite ver los temas más comunes en los opinión de los clientes, independientemente de la categorización del tema.
Las palabras asociadas se presentan en el siguiente formato: palabra 1 → palabra 2.
Ejemplo: Si el opinión de un cliente fue “La tienda estaba sucia” y lo agrupas por palabras asociadas, verás “tienda → sucia” en tu widget.
Hashtags
El Hashtags La agrupación le permite agrupar datos por hashtags y frases (palabras o frases con el prefijo “. # símbolo). Los hashtags suelen utilizarse en publicaciones en redes sociales para ayudar a identificar y categorizar el sujeto de la publicación.
Enriquecimiento
El Enriquecimiento Las agrupaciones le permiten agrupar datos según los tipos de contenido incluidos en los opinión de los clientes. Están disponibles las siguientes agrupaciones:
- Capítulos de CB:Agrupar datos por conversacional capítulos que representan segmentos semánticamente relacionados de la conversación (como Apertura, Necesidad, Verificación, Paso de solución y Cierre).
- Subtipo de contenido CB: Grupo adicional Sin contenido datos por sus subtipos (como anuncios, cupones, enlaces a artículos o tipo “indefinido”). Tenga en cuenta que para los registros con contenido, el subtipo siempre también tiene contenido.
- Tipo de contenido CB:Agrupar datos por su naturaleza Con contenido o sin contenido como lo identifica automáticamente XM Discover.
- Características detectadas por CB:Agrupe los datos por tipos de características de PNL detectadas (por ejemplo, datos que contienen menciones de la industria o la marca/organización ).
- Emoción CB:Agrupar datos por emoción tipos detectados por el motor de PNL (como ira, confusión, decepción, vergüenza, miedo, frustración, celos, alegría, amor, tristeza, sorpresa, agradecimiento, confianza u otros).
- Condición médica de CB:Agrupe datos según las condiciones médicas mencionadas en el texto (por ejemplo, “covid” o “meningitis”).
- Procedimiento médico de CB:Agrupe datos según los procedimientos médicos mencionados en el texto (por ejemplo, “mamografía” o “cirugía de espalda”).
- Puntuación de empatía de los Participante del CB:Agrupe los datos conversacionales en función de si los representantes mostraron empatía en sus interacciones con los clientes o no. 0 significa que el representante no mostró empatía, mientras que 1 significa que el representante mostró empatía.
- Razón de CB:Agrupar datos según motivos para un evento de conversación en particular (por ejemplo, motivo de contacto o motivo de empatía).
- Receta CB:Agrupe los datos por los nombres de los medicamentos mencionados en el texto (por ejemplo, “acetaminofén” o “tylenol”).
- Tipo de oración CB:Agrupe los datos por tipo de oración o intención (por ejemplo, “grito de ayuda” o “sugerencia”).
Idioma
El Idioma Las agrupaciones le permiten agrupar datos según el idioma en el que se dejaron los opinión . Están disponibles las siguientes agrupaciones:
- Idioma detectado automáticamente por CB:Agrupar datos por idiomas detectados automáticamente (si la detección automática de idiomas está habilitada para un proyecto).
- Lenguaje procesado CB:Agrupe los datos por idiomas en los que realmente se procesó la opinión . Los idiomas no compatibles con la detección de idiomas de XM Discover están marcados como “otros”.
Conversación
El Conversación Las agrupaciones le permiten agrupar datos según diversos enriquecimientos conversacionales. Tenga en cuenta que estas agrupaciones solo están disponibles para datos conversacionales (llamadas y chats procesados mediante Qualtrics). formato conversacional). Están disponibles las siguientes agrupaciones:
- CB % Silencio:Agrupa datos según el porcentaje de silencio en una llamada.
- Duración de la conversación CB:Agrupa datos según la duración de una conversación en milisegundos. Para las llamadas, este es el tiempo transcurrido entre el inicio de la primera oración y el final de la última oración. Los silencios iniciales y finales no se cuentan. Para los chats, este es el tiempo transcurrido entre la primera oración y la última oración.
- CB Tipo de Participante:Agrupa datos por tipo de participante. Los valores posibles incluyen:
- robot de chat es un chatbot.
- Respuesta de voz interactiva (IVR) es un bot de respuesta de voz interactiva.
- Humano es una persona
- Tipo de Participante del CB:Agrupa datos por tipo de participante. Los valores posibles incluyen:
- agente es un representante de la empresa o un chatbot.
- cliente Es un cliente.
- tipo_desconocido es un participante no identificado como agente o cliente.
- Duración de la oración CB:Agrupa datos por la duración de una oración en una llamada en milisegundos.
- Hora de inicio de la oración CB:Agrupa datos por la marca de tiempo del inicio de la oración. Para las llamadas, este es el tiempo en milisegundos desde el inicio audible de la primera palabra en la primera oración. Para los chats, este es el tiempo en milisegundos desde que se envía el primer mensaje. Consejo Q: El tiempo de inicio del primer mensaje de chat siempre será 0 ms para este atributo.

- Aire muerto total de CB:Agrupa datos según el tiempo muerto total en una llamada en milisegundos. En las llamadas, el aire muerto es una pausa larga entre los hablantes.
- CB Vacilación total:Agrupa datos según la vacilación total (del agente y del cliente) en una llamada en milisegundos. En las llamadas, la vacilación es una pausa prolongada por parte de uno de los hablantes.
- Sobreconversación total de CB:Agrupa datos por la longitud acumulada de oraciones superpuestas en una llamada en milisegundos. En las llamadas, se considera sobreconversación cualquier momento en el que dos o más hablantes están hablando simultáneamente y las marcas de tiempo de sus oraciones se superponen.
- CB Silencio Total:Agrupa datos según la duración acumulada de todos los silencios mayores o iguales a 2 segundos entre oraciones para todos los participantes en una llamada en milisegundos.
Hora
Seleccionando Tiempo Permite agrupar datos por periodos de tiempo. Puede utilizar agrupaciones de atributo de tiempo para crear un informe de tendencias, lo que le permitirá ver cómo sus cálculos y métricas cambian con el tiempo.
Atributos
Seleccionando Atributos le permite agrupar datos por los valores de un atributo estructurado seleccionado. Un atributo estructurado es cualquier campo numérico o de cadena presente en un registro que no es la opinión textual real. Los atributos estructurados generalmente contienen datos discretos con un alto grado de organización (como la edad de una persona o el nombre del producto que utiliza). Los atributos disponibles para la agrupación dependen de la fuente de opinión y generalmente varían de un conjunto de datos a otro.
Ejemplo: Puedo agrupar por el Atributo “Agente” para ver agrupaciones de interacciones por los diferentes agentes que manejaron la interacción.
Métricas
Seleccionando Métrica permite agrupar datos por valores discretos o bandas de ciertos cálculos estándar y métricas derivadas. En otras palabras, puedes organizar los datos según una métrica y medirlos según otra métrica diferente. Están disponibles las siguientes agrupaciones:
- Sentimiento (3 bandas):Agrupe los datos por 3 bandas de sentimiento (negativo, neutral, positivo). Ver Agrupación por Sentimiento Para más información.
- Sentimiento (5 bandas):Agrupe los datos por 5 bandas de sentimiento (Fuertemente negativo, Negativo, Neutral, Positivo, Fuertemente positivo). Ver Agrupación por Sentimiento Para más información.
- Esfuerzo (3 bandas):Agrupa los datos por 3 bandas de esfuerzo (Duro, Neutral, Fácil). Al agrupar por esfuerzo, se incluyen valores nulos de forma predeterminada.
- Esfuerzo (5 bandas):Agrupa los datos en 5 bandas de esfuerzo (Muy duro, Duro, Neutro, Fácil, Muy fácil). Al agrupar por esfuerzo, se incluyen valores nulos de forma predeterminada.
- Intensidad emocional:Agrupa los datos en 3 bandas de intensidad emocional (Baja, Media, Alta).
- Recuento de palabras del documento CB:Agrupa datos por la cantidad de palabras de un documento.
- Duración de la lealtad del CB:Agrupar datos según la duración de la fidelidad del cliente (en años).
- Cuartil de oración CB:Agrupe los datos según el cuarto de la secuencia literal en que se encuentra una oración (1, 2, 3 o 4). Esto puede ayudarle a comprender qué temas se están discutiendo en qué puntos de la conversación.
- Recuento de palabras de la oración CB:Agrupa datos por el número de palabras en una oración.
Además, puedes definir tu propio Cuadro superior, cuadro inferior y métricas de satisfacción por el cual puedes agrupar datos. Esto le permite determinar si los opinión provienen de un promotor, un detractor o un cliente neutral. Están disponibles las siguientes agrupaciones:
- Caja superior:Agrupar datos por bandas de caja superior (promotores y otros).
- Caja inferior:Agrupar datos por bandas del cuadro inferior (detractores y otros).
- Satisfacción:Agrupar datos por bandas de satisfacción (detractores, neutrales, promotores).
Impulsores
Consejo Q: Solo puedes utilizar controladores en widgets de gráfico de dispersión.
Seleccionando Conductores le permite agrupar datos por Conductores usted crea en su cuenta. Puede utilizar estos controladores para encontrar atributos y temas que conduzcan a un resultado determinado.
Jerarquía de la organización
Seleccionando Jerarquía de la Organización Permite agrupar datos por los diferentes niveles en el seleccionado. jerarquía organización.
Costo de agrupación
Al ejecutar informes con múltiples agrupaciones, es posible que reciba el siguiente mensaje de error:
“¡Ups! aplicar un costo estimado a cada agrupación, y la suma de costos no puede exceder el presupuesto de protección de [10.5]. (Las agrupaciones de alta cardinalidad cuestan más). Elimine o elija diferentes agrupaciones según los costos que se enumeran a continuación para garantizar que el widget tenga un costo total dentro del presupuesto: [lista de agrupaciones y sus costos] Costo total actual: [total de todos los costos]”
El costo de cada agrupación depende de la cantidad de valores únicos en el grupo (esta medida se llama cardinalidad). De forma predeterminada, la mayoría de los widgets devuelven los 10 elementos principales por volumen. Si hay 100 elementos en total, este cálculo suele ser muy rápido. Si hay 1.000.000 de artículos, entonces lleva más tiempo calcular cuáles de ellos son los 10 primeros. En general, tener más elementos únicos resultados en un cálculo más costoso en términos de rendimiento. Este costo puede multiplicarse rápidamente para los widgets que devuelven múltiples niveles de datos y puede provocar que aparezca el mensaje de error anterior.
Si recibe el error anterior al utilizar agrupaciones en un informe, debe eliminar una o más de las agrupaciones enumeradas para que su costo total no exceda el presupuesto. El mensaje de error mostrará los costos estimados para cada agrupación para ayudarle a decidir qué agrupación eliminar.
¡Genial! ¡Gracias por tus comentarios!
¡Gracias por tus comentarios!