Análisis de clústeres
Contenidos de la página
Acerca del análisis de Clúster
Cuando analizamos nuestros datos, a menudo nos preocupamos por diferentes grupos demográficos y segmentamos a los encuestados por ingresos, región, edad y más. Pero a veces estas etiquetas pueden ser reductivas: después de todo, saber que hay muchos encuestados hombres no te dice qué tipo de campaña publicitaria les gustaría ver. ¿Su audiencia es principalmente millennials? ¿Papás futbolistas? ¿Ambos? ¿Cómo poner las características personales en términos que puedan desglosarse para fines de marketing?
El análisis de Clúster es un medio para detectar los grupos que aparecen naturalmente en el conjunto de datos de su encuesta. Esto se hace analizando qué cualidades demográficas, conductuales y/o basadas en creencias están más altamente correlacionadas.
{kind=link}
Consejo Q: Puedes tener hasta 750 tarjetas en tu espacio de trabajo. Si alcanzas este límite, aparecerá un error cuando intentes crear una nueva tarjeta, advirtiéndote que tus tarjetas más antiguas serán eliminadas.
Preparación de una Encuesta para el análisis de Clúster
Para realizar un análisis de clúster , es necesario recopilar los datos correctos en su encuesta.
- Haga las preguntas correctas:
- Demografía: Pregunte sobre información descriptiva básica, como edad, nivel de ingresos, raza o género.
- Comportamiento: Pregunte cómo interactúan los clientes con su marca/organización y sus productos, o sobre comportamientos que puedan estar relacionados con su comportamiento de compra. Por ejemplo, puedes preguntar con qué frecuencia el cliente va de compras.
- Operacional Datos: Se trata de información como el tiempo que un empleado pasa en su sitio web o la antigüedad de un empleado en su empresa. Consejo Q: ¿Está interesado en realizar un seguimiento del tiempo invertido en una página?Entonces quizás te interese utilizar nuestro Opinión el sitio web función. Contacto con tu Ejecutivo de Cuenta Si estás interesado en aprender más.

- Actitudes y creencias: Encuesta a sus encuestados sobre sus valores fundamentales, actitudes y creencias. Esto puede incluir creencias religiosas o políticas, pero también puede preguntar sobre creencias directamente relevantes para el funcionamiento de su empresa. Por ejemplo, puedes pedirles que califiquen la importancia de que las interacciones de soporte sean cara a cara.
- Formatos de preguntas: Formatear preguntas sobre comportamientos y creencias como balanza . El rango de una escala puede ayudarnos a entender qué puntos de la escala están correlacionados y, por lo tanto, aproximadamente en el mismo clúster; las preguntas de Sí/No y de selección única no son tan útiles para el análisis de clúster . Ejemplo: Si preguntas “¿Qué tipo de comprador eres?” y das las opciones “Prefiero comprar en centros comerciales”, “Prefiero comprar en línea” y “Prefiero comprar en boutiques”, el algoritmo de agrupamiento querrá dividir a los encuestados en tres grupos, uno para cada respuesta. Si, en cambio, las formulara como una serie de preguntas (por ejemplo, “¿Le gusta ir de compras a centros comerciales?”) con respuestas del 1 al 7, el algoritmo de agrupamiento hará un mejor trabajo para discernir realmente qué separa a los diferentes compradores entre sí.
 Consejo Q: Opción múltiple Las preguntas son las mejores para recopilar datos escalares.
Consejo Q: Opción múltiple Las preguntas son las mejores para recopilar datos escalares. - Tipos de variables : Cuando esté listo para analizar en Stats iQ, asegúrese de formatear sus variables como Categorías o números . Las fechas son incompatibles con el análisis de clúster .
Consejo Q: Al crear sus variables, considere aquellas que ya sabe que están altamente correlacionadas. Esto le ayudará a permanecer dentro del límite de 10 variables en el análisis de clúster .
Atención: El análisis de Clúster tiene un tamaño de muestra máximo de 20.000 respuestas.
Realizar análisis de Clúster
Consejo Q: Sólo se puede realizar un análisis de clúster en 10 variables a la vez. Si desea incluir más, intente encontrar variables que estén altamente correlacionadas entre sí y cree un promedio de ellas utilizando el Crear o limpiar variable botón y.
Resultados del análisis de Clúster
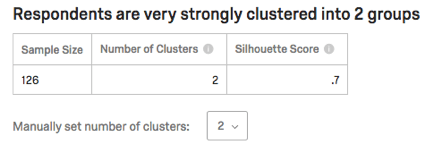
Tabla de resistencia y estática
La tabla lista el tamaño de la muestra (cuántos encuestados aportaron datos a este análisis), la cantidad de grupos y la puntuación de silueta. La puntuación de la silueta se interpreta en frases como “muy fuertemente” en la oración de la parte superior.
{kind=link}
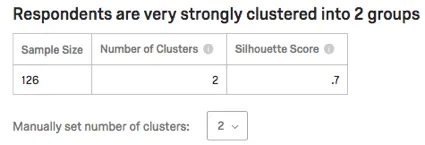
Consejo Q: Para obtener más información sobre la puntuación de silueta que se muestra en esta tabla, consulte la sección Interpretación del análisis de Clúster .
El análisis de Clúster intenta elegir automáticamente la cantidad apropiada de conglomerados evaluando la estrechez de la agrupación en distintos números, pero penalizando una mayor cantidad de conglomerados por ser más difíciles de trabajar. Elegir el número correcto es más un arte que una ciencia, y debes experimentar con diferentes números para ver cuál funciona mejor.
En algunos casos, el algoritmo no podrá producir una determinada cantidad de clústeres y recurrirá a una cantidad menor.
Resumen de clústeres
Sus clústeres aparecerán en la sección Resumen de Clúster . Se describirán en función de las preguntas que los miembros del clúster respondieron de forma más similar.
{kind=link}

Ejemplo: El Clúster 1 en esta captura de pantalla contiene personas que son:
- Casado
- Tener título de maestría
- Tienen pocas personas (familiares inmediatos, niños) viviendo en su casa.
- Joven
Haga clic en el nombre de un clúster para cambiarle el nombre.
Consejo Q: Cambiar el nombre de sus clústeres es importante para que sus resultados tengan más sentido en un contexto de marketing o del mundo real.

{kind=link}
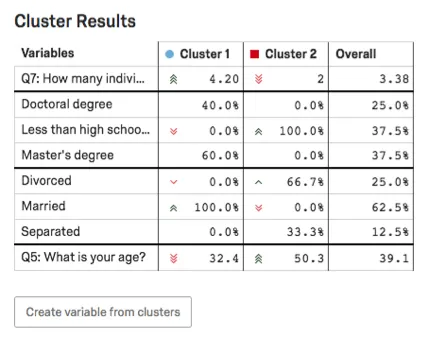
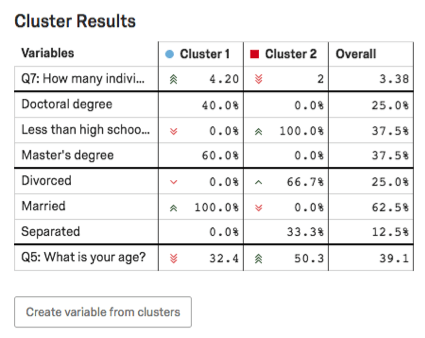
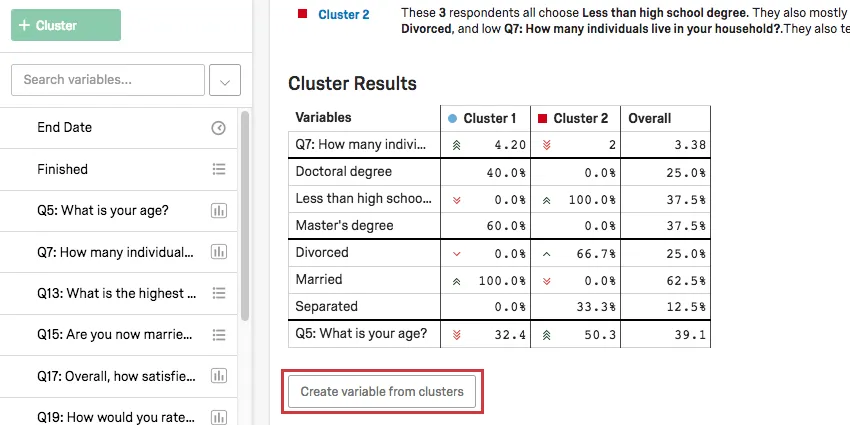
Tabla de Resultados de Clúster
En la Tabla de resultados del Clúster , se resaltarán las principales variables del clúster . Para las variables categóricas, se dará la opción más común y el porcentaje de encuestados en el clúster que proporcionaron esta respuesta.Para las variables numéricas, verá una respuesta promedio.
Ejemplo: En esta captura de pantalla, el nivel de educación es categórico, por lo que vemos un desglose de los porcentajes de encuestados con títulos de doctorado frente a los de otros. Menos que una educación secundaria vs. Maestrías.
Aquí la edad es numérica, por lo que vemos la edad promedio para cada clúster (32,4 para el Clúster 1, 50,3 para el Clúster 2).
{kind=link}
Para obtener más información sobre cómo crear variables a partir de clústeres, consulte la sección Crear variable a partir de clústeres.
Importancia de la variable
La tabla de importancia de las variables muestra la fuerza de la relación entre cada variable y los grupos. Una relación más fuerte indica que la variable fue más importante en la creación de los clústeres.
Para calcular esto, ejecutamos regresiones para cada variable. Por ejemplo, compararíamos la edad con el resultado del clúster , las horas trabajadas con el resultado del clúster , y así sucesivamente.
Los valores r-cuadrados resultantes de esas regresiones se amplían luego de modo tal que el r-cuadrado más alto se establece en 1.
Ejemplo: Digamos que Q7 tuvo un r cuadrado de 0,5, el más alto del grupo. Necesitamos duplicar eso para establecerlo en 1. Eso significa que si Q13 tuviera un r cuadrado de 0,4, aparecería como 0,8 en el gráfico siguiente.

{kind=link}
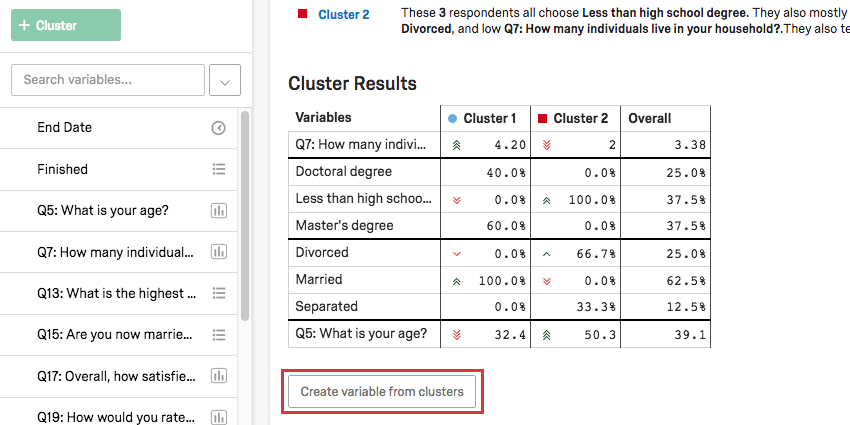
Creación de nuevas variables a partir de los Resultados
Una vez que haya determinado los grupos entre sus encuestados, puede convertir estas categorías en nuevas variables que puede analizar en Stats iQ.
Primero, asegúrese de Cambie el nombre de sus clústeres haciendo clic en sus nombres.

Consejo Q: El paso de cambio de nombre no es obligatorio, pero hará que sus datos estén más limpios y sean más comprensibles para usted y sus colegas.
Una vez que sus clústeres tengan nombres que tengan sentido para usted, haga clic en Crear variable a partir de clústeres en la Tabla de resultados del Clúster . Esto agregará automáticamente una variable categórica a su lista de variables de la izquierda.
{kind=link}
Consejo Q: Esta variable sólo está disponible en Stats iQ. No aparecerá en ningún otro lugar de sus datos de Qualtrics .
Notas técnicas
El análisis de Clúster en Stats iQ utiliza el análisis de clases latentes (LCA) para particionar los datos proporcionados por el usuario en sus clústeres subyacentes. A diferencia de otros algoritmos de agrupamiento, el algoritmo LCA de Stats iQ permite agrupar tipos de datos mixtos (numéricos, categóricos y binarios).
Análisis de clases latentes de tipo mixto
El análisis de clases latentes (LCA) es un modelo de agrupamiento basado en probabilidad. Cada clúster se define mediante una colección de funciones de densidad de probabilidad que, en función del valor de las variables de un punto de datos, devuelve la probabilidad de que un punto de datos particular pertenezca a ese clúster.
Ejemplo: Su familia puede dividirse en varias generaciones, como los hijos actuales, los padres y los abuelos. Un modelo LCA representaría estos tres grupos, donde cada clúster está definido por una única función de probabilidad basada en la edad:
Clúster Función de probabilidad media Función de probabilidad Desviación estándar Actual 25 7 Padres 48 5 Abuelos 75 3 Para asignar a alguien de 30 años a un clúster, utilice estas funciones de densidad de probabilidad para calcular que hay un 44 % de probabilidad de que esté en Actual, un <1 % de probabilidad de que esté en Padres y un <1 % de probabilidad de que esté en Abuelos. Este individuo sería asignado a su clúster más probable, Actual.
Un modelo LCA se puede aplicar a múltiples variables multiplicando la probabilidad de que un punto de datos pertenezca a un clúster en función de cada variable. El modelo se puede aplicar a diferentes tipos de variables utilizando diferentes funciones de densidad de probabilidad:
| Tipo | Transformación | Función de densidad de probabilidad |
|---|---|---|
| Categórico | Codificación ficticia (N-1) | Bernoulli |
| Binario | Bernoulli | |
| Numérico | Normal |
Determinación del número de clases
Para determinar el número óptimo de clases, Stats iQ utiliza una puntuación BIC.
Evaluación del ajuste del modelo
Para evaluar la “bondad” objetiva de un modelo, Stats iQ utiliza una puntuación de silueta basada en probabilidad. Una puntuación de silueta es una medida de qué tan bien se ubica cada punto de datos dentro de su clúster. Una puntuación de silueta mide la similitud de un punto particular con todos los demás puntos de su clúster y la compara con su similitud con todos los puntos de su clúster vecino más cercano. Para medir la similitud entre dos puntos de datos, Stats iQ calcula la distancia de Gower (una métrica de distancia que funciona para datos binarios, categóricos y numéricos) entre los puntos.
Preguntas frequentes
¿Cómo consigo que mis nuevas respuestas aparezcan en Stats iQ?
¿Cómo consigo que mis nuevas respuestas aparezcan en Stats iQ?
¿Qué hago si mis datos no se cargan correctamente?
¿Qué hago si mis datos no se cargan correctamente?
¡Genial! ¡Gracias por tus comentarios!
¡Gracias por tus comentarios!