-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Conector de entrada de XM Discover Link
Acerca del conector de entrada XM Discover
Puede utilizar el conector entrante de enlace XM Discover para enviar datos de XM a XM Discover a través de un punto final de API REST y, al mismo tiempo, aprovechar todas las capacidades que ofrece el marco de conectores, como mapeo de campos, transformaciones, filtros, observación de trabajos, etc.
Formatos de datos admitidos
Los siguientes tipos de datos son compatibles con Solo formato JSON:
Antes de configurar el conector, cree un archivo de muestra que represente los campos que desea importar a XM Discover. Consulte las páginas vinculadas arriba para obtener más información sobre los campos obligatorios y los formatos de archivo.
También hay archivos de plantilla disponibles para descargar dentro del conector para formatos de datos específicos:
- Chats
- Chat (predeterminado):Se utiliza para datos de interacciones digitales estándar.
- Conexión de Amazon:Úselo para interacciones digitales específicas de Amazon Connect Chat.
- Llamar
- Llamada (predeterminado):Se utiliza para datos de transcripciones de llamadas estándar.
- Verint: Úselo para transcripciones de llamadas específicas de Verint.
- Opinión
- Dinámica 365:Se utiliza para datos de Microsoft Dynamics.
Creación de un trabajo de conector de entrada de enlace de XM Discover
- En la pestaña Trabajos, haga clic en Nuevo trabajo .
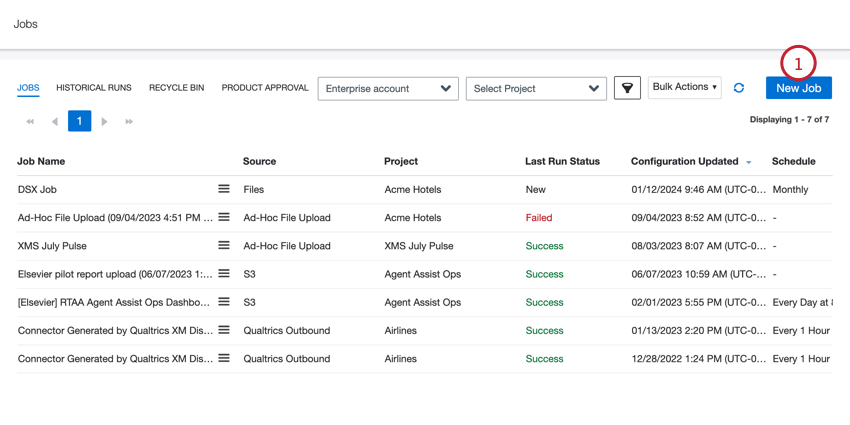
- Haga clic en el Enlace de XM Discover trabajo.

- Dale un nombre a tu trabajo para que puedas identificarlo.
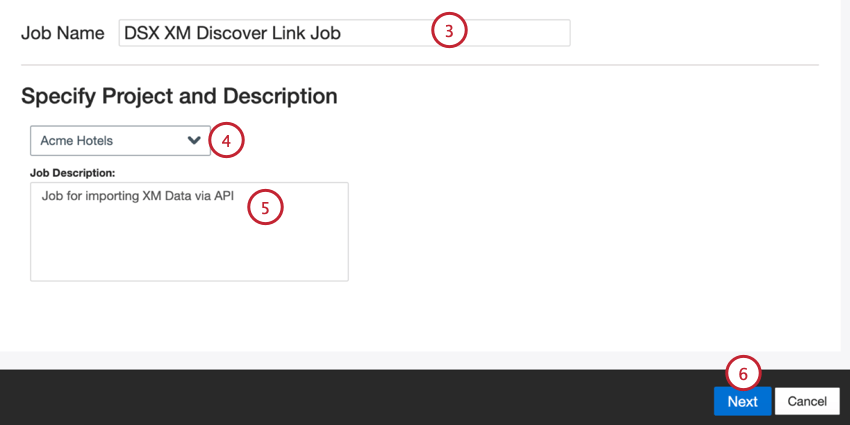
- Seleccione el proyecto en el que desea cargar datos.
- Dale una descripción a tu trabajo para que conozcas su propósito.
- Haga clic en Siguiente.
- Elige tu modo de autorización, o cómo te conectarás a XM Discover:
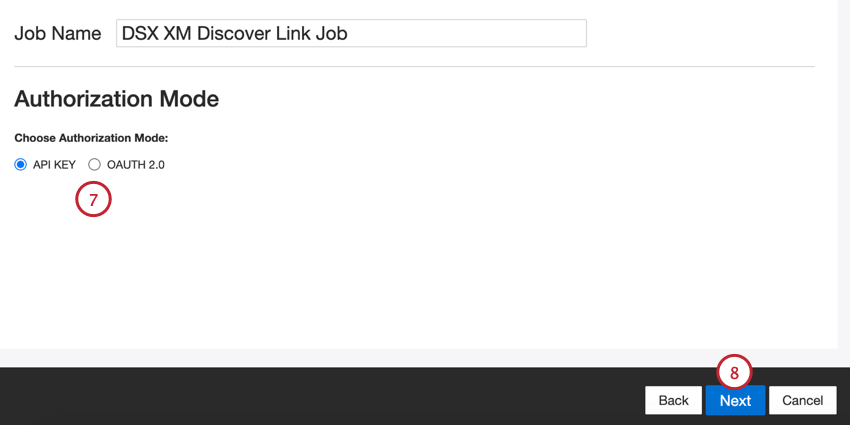
- Clave API:Conéctese usando un token de API de XM Discover.
- OAuth 2.0:Conéctese utilizando un ID de cliente y un secreto de cliente proporcionados por el servicio de autenticación XM Discover . Contacto con su representante de Discover para solicitar este método.
Consejo Q:Puede contacto con su representante de Discover directamente por correo electrónico. Si no tienes su información de contacto , puedes contacto con el Discover el equipo de soporte en cambio.
- Haga clic en Siguiente.
- Elige el formato de tus datos: chat (digital), llamada o opinión.
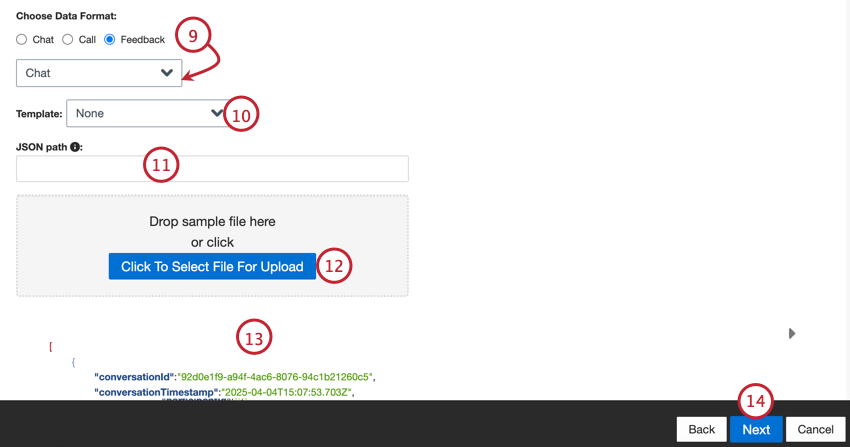 Consejo Q: Si seleccionó “opinión”, aparecerá un segundo menú para que elija el tipo de datos de interacción incluidos en la opinión. Las opciones incluyen llamada, chat, correo electrónico, revisión, redes sociales y encuesta.
Consejo Q: Si seleccionó “opinión”, aparecerá un segundo menú para que elija el tipo de datos de interacción incluidos en la opinión. Las opciones incluyen llamada, chat, correo electrónico, revisión, redes sociales y encuesta. - Si lo desea, elija una plantilla y luego haga clic en el aquí Enlace para descargar el archivo de plantilla.
- Entrar en el Ruta JSON a un subconjunto de JSON que contiene nodos de documentos. Deje este campo vacío si los documentos están ubicados en el nivel del nodo raíz.
- Haga clic en el Haga clic para seleccionar el archivo que desea cargar Botón y seleccione el archivo de muestra en su computadora.
- Aparecerá una vista previa del archivo. Si ve un mensaje de error o el contenido del archivo sin procesar en lugar de la vista previa, es posible que haya un problema con las opciones de formato de datos que seleccionó. Ver Errores de archivos de Muestra para obtener ayuda para solucionar problemas con su archivo.
- Haga clic en Siguiente.
- Si es necesario, ajuste su asignaciones de datos . Ver el Página de soporte de mapeo de datos para obtener información detallada sobre el mapeo de campos en XM Discover. El Asignación de datos predeterminada La sección contiene orientación específica para este conector.
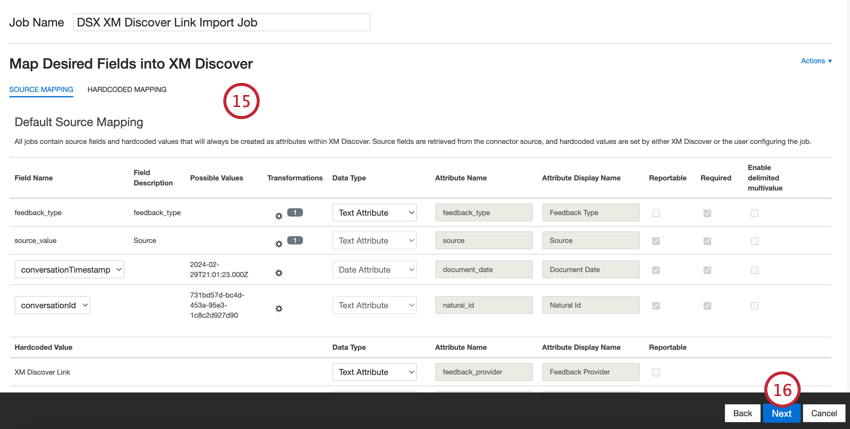
- Haga clic en Siguiente.
- Si lo desea, puede agregar Reglas de sustitución y redacción de datos para ocultar datos confidenciales o reemplazar automáticamente ciertas palabras y frases en los opinión e interacciones de los clientes. Ver el Página de soporte para la sustitución y redacción de datos Para más información.
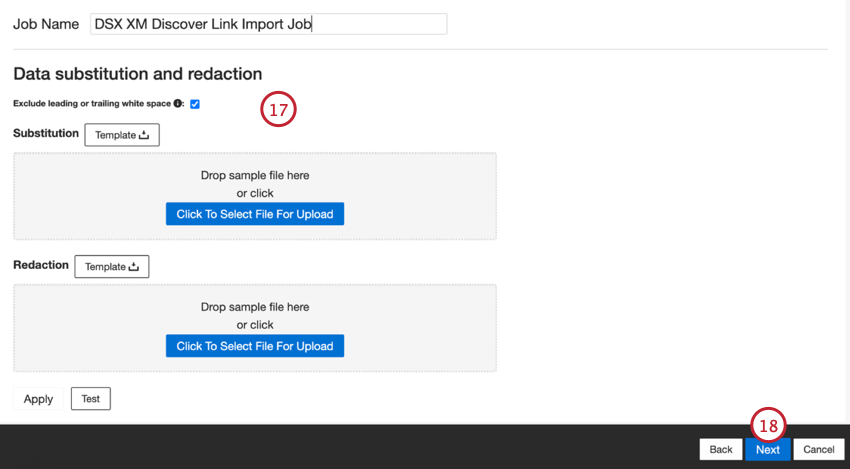
- Haga clic en Siguiente.
- Si lo desea, puede agregar un filtro de conector para filtro los datos entrantes y limitar qué datos se importan.
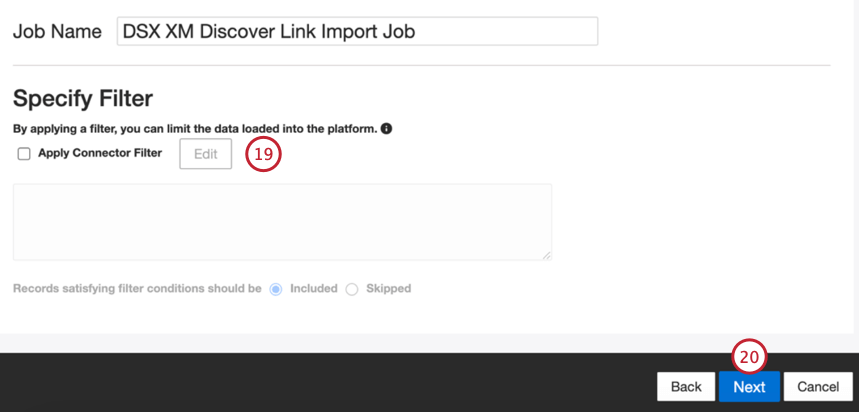
- Haga clic en Siguiente.
- Elija cómo se gestionarán los documentos duplicar . Ver Manejo de Duplicar Para más información.
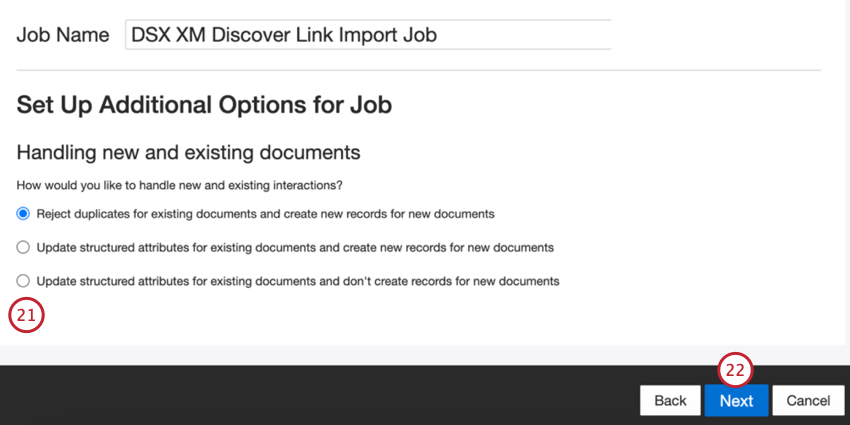
- Haga clic en Siguiente.
- Revise su configuración. Si necesita cambiar una configuración específica, haga clic en el Editar Botón para ir a ese paso en la configuración del conector.
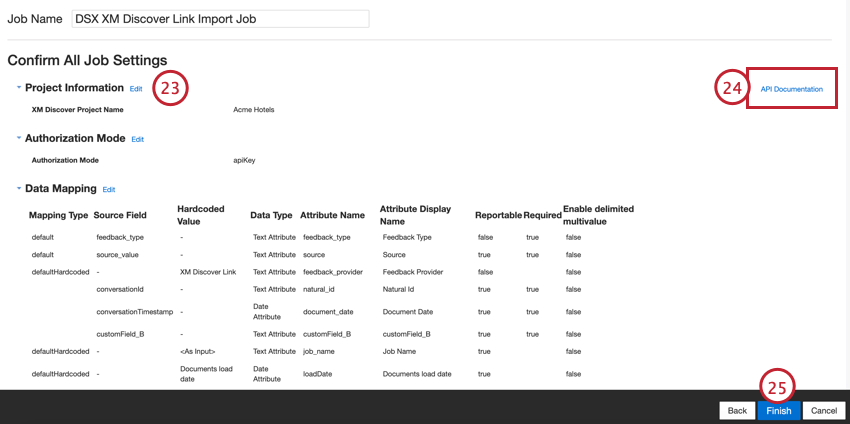
- El Documentación API El enlace contiene su punto final de API , que se utilizará para enviar datos a XM Discover. Ver Acceder al punto final de la API Para más información.
- Hacer clic Finalizar para guardar su configuración.
Asignación de datos predeterminada
Esta sección contiene información sobre los campos predeterminados para los trabajos de enlace entrante de XM Discover .
Al asignar sus campos, estarán disponibles los siguientes campos predeterminados:
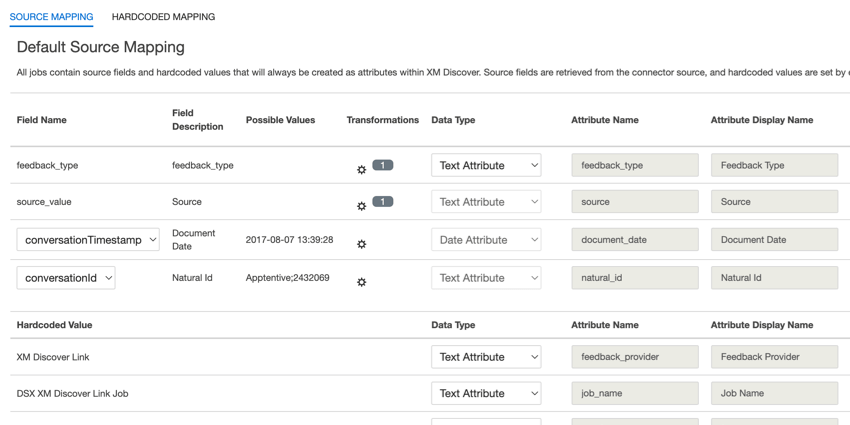
- tipo_de_retroalimentación: El tipo de Opinión le ayuda a identificar datos según su tipo. Esto es útil para generar informes cuando su proyecto contiene diferentes tipos de datos (por ejemplo, encuestas y opinión en las redes sociales). Este campo es editable. De forma predeterminada, el valor de este atributo se establece en:
- “llamada” para transcripciones de llamadas
- “Chat” para interacciones digitales
- “opinión” para opinión individuales
- Puedes utilizar transformaciones personalizadas para establecer un valor personalizado.
- fuente:Fuente le ayuda a identificar datos obtenidos de una fuente específica. Esto puede ser cualquier cosa que describa el origen de los datos, como el nombre de una encuesta o una campaña de marketing móvil. Este campo es editable. De forma predeterminada, el valor de este atributo se establece en “XM Discover Link”. Puede utilizar una transformación personalizada para establecer un valor personalizado.
- ricoVerbatim:Este campo se utiliza para datos de conversación (como transcripciones de llamadas y chats) y no es editable. XM Discover utiliza un formato verbatim conversacional para el campo richVerbatim. Este formato admite la ingesta de metadatos específicos del diálogo necesarios para desbloquear la visualización conversacional (turnos de conversación, silencio, eventos conversacionales, etc.) y enriquecimientos (hora de inicio, duración, etc.). Este campo textual incluye campos “secundarios” para realizar un seguimiento de la conversación del lado del cliente y del representante:
- clienteVerbatim rastrea el lado del cliente de la conversación.
- agenteVerbatim rastrea el lado de la conversación del representante (agente).
- desconocido rastrea el lado desconocido de la conversación.
-
Consejo Q: No se admiten transformaciones para campos textuales conversacionales. No se puede utilizar el mismo verbatim para diferentes tipos de datos conversacionales. Si desea que su proyecto albergue varios tipos de conversación, utilice pares separados de frases textuales conversacionales por tipo de conversación.
- clienteVerbatim:Este campo se utiliza para datos conversacionales y es editable. Este campo rastrea el lado del cliente de la conversación en las interacciones de llamadas y chat. De forma predeterminada, este campo se asigna a:
- clienteVerbatimChat para interacciones digitales.
- clienteVerbatimCall para interacciones de llamadas.
- agenteVerbatim:Este campo se utiliza para datos conversacionales y es editable. Este campo rastrea la parte del representante de la conversación en las interacciones de llamadas y chat. De forma predeterminada, este campo se asigna a:
- agenteVerbatimChat para interacciones digitales.
- agenteVerbatimCall para interacciones de llamadas.
- desconocido:Este campo se utiliza para datos conversacionales y es editable. Este campo rastrea el lado desconocido de la conversación en las interacciones de llamadas y chat. De forma predeterminada, este campo se asigna a:
- desconocidoVerbatimChat para interacciones digitales.
- desconocidoVerbatimCall para interacciones de llamadas.
- fecha del documento:La fecha del documento es el campo de fecha principal asociado con un documento. Esta fecha se utiliza en informes , tendencias, alertas, etc. de XM Discover . Para la fecha del documento, elija una de las siguientes opciones:
- ConversaciónMarca de tiempo (para datos conversacionales): Fecha y hora de toda la conversación.
- Si los datos de origen contienen otros campos de fecha, puede establecer uno de ellos como fecha del documento seleccionándolo en el menú desplegable. Nombre del campo.
- También puedes establecer una fecha específica agregando un campo personalizado.
- identificación natural:Natural ID sirve como identificador único de un documento y permite procesar duplicados correctamente. Para identificación natural, elija una de las siguientes opciones:
- ID de conversación (para datos conversacionales): una identificación única para toda la conversación.
- Seleccione cualquier campo de texto o numérico de sus datos en el Nombre del campo.
- Generar identificaciones automáticamente agregando un campo personalizado.
- proveedor de retroalimentación:El proveedor de Opinión le ayuda a identificar los datos obtenidos de un proveedor específico. Para las cargas de XM Discover Link, el valor de este atributo se establece en “XM Discover Link” y no se puede editar.
- nombre_del_trabajo:El nombre del trabajo le ayuda a identificar datos según el nombre del trabajo utilizado para cargarlos. Puede modificar el valor de este atributo en el Nombre del puesto cuadro en la parte superior de la página o utilizando el Menú de opciones de trabajo.
- Fecha de carga:La fecha de carga indica cuándo se cargó un documento en XM Discover. Este campo se configura automáticamente y no se puede editar.
Además de los campos anteriores, también puedes asignar cualquier campo personalizado que desees importar. Ver el Página de soporte de mapeo de datos para obtener más información sobre los campos personalizados.
Acceder al punto final de la API
El punto final de API se utiliza para cargar datos a XM Discover enviándolos a través de una solicitud de API REST en formato JSON .
Puede acceder al punto final desde la página Trabajos:
- Seleccionar Resumen en el menú de opciones de trabajo para su trabajo.
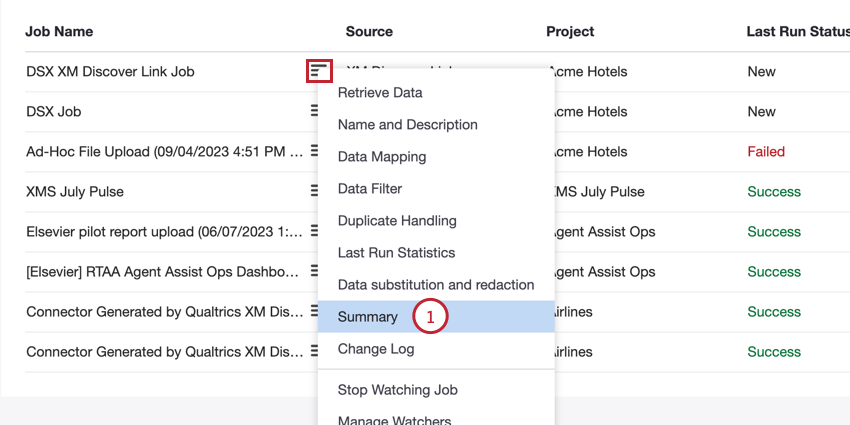
- Haga clic en el Documentación API enlace.

- Haga clic en el Imprimir Botón para descargar toda la información de esta ventana como PDF imprimible.
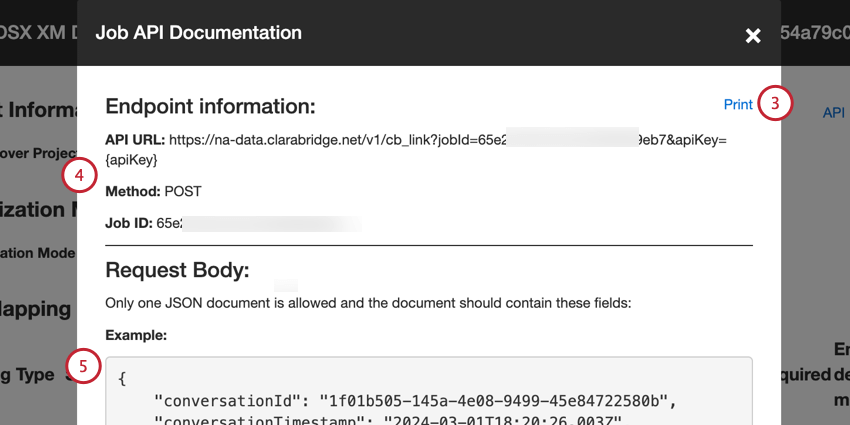
- Su información del punto final incluye:
- URL de la API:La URL utilizada para la solicitud de API .
- Método:Utilice el CORREO método para cargar datos en XM Discover.
- Identificación del trabajo:El ID del trabajo seleccionado actualmente.
- Se incluye un ejemplo de carga útil JSON en el Cuerpo de la solicitud sección. Una solicitud de API debe contener solo 1 documento y solo incluir los campos en la carga útil de ejemplo.
- El Respuestas La sección enumera las posibles respuestas de éxito y error de la solicitud de API .
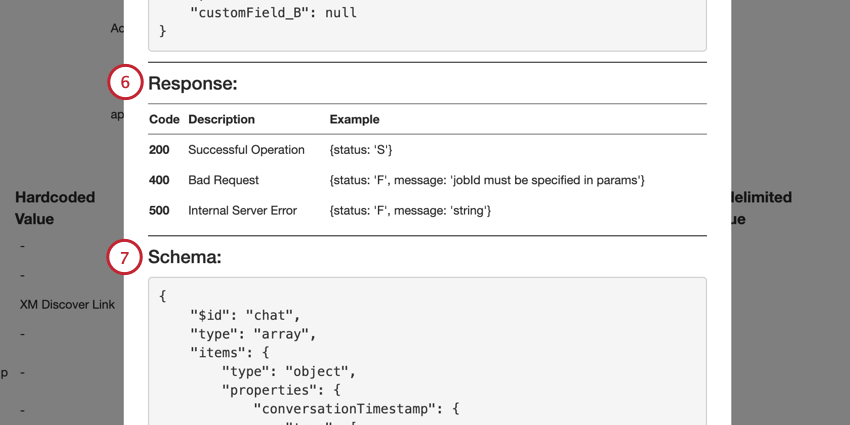
- El Esquema La sección muestra el esquema de datos. Los campos obligatorios están en el requerido formación.
Monitoreo de un trabajo de XM Discover Link a través de API
Puede monitorear el estado de los trabajos de XM Discover Link sin iniciar sesión en XM Discover llamando al punto final de la API de estado. Esto le permite obtener el último estado de ejecución de trabajo, métricas para una ejecución de trabajo específica o métricas acumuladas para un período de tiempo específico.
Información del punto final de estado
Para llamar al punto final de estado, necesitará lo siguiente:
- URL de la API: https://na-data.clarabridge.net/v1/public/job/status/<jobID>?apiKey=<apiKey>
- <jobId> es el ID del trabajo XM Discover Link que desea monitorear.
- <apiKey> es el token de API.
- Tipo:Utilice el REST HTTP
- Método HTTP: Utilice el método GET para recuperar datos.
Elementos de entrada
Los siguientes elementos de entrada opcionales se pueden utilizar para recuperar métricas adicionales sobre su trabajo:
- ID de ejecución histórica:El ID de la sesión de carga específica. Si se omite este elemento y no se proporciona ningún rango de fechas, la llamada API devuelve el último estado de ejecución del trabajo. Si se omite este elemento y se proporciona un rango de fechas, la llamada API devuelve métricas acumuladas para el período de tiempo especificado.
- Fecha de inicio:Defina la fecha de inicio a partir de la cual se devolverán los datos.
- Fecha de finalización:Defina la fecha final para devolver los datos en función de la última carga. Si se omite este elemento y se proporciona startDate, endDate se establece automáticamente en la fecha actual.
Elementos de salida
Se devolverán los siguientes elementos de salida, siempre que haya ingresado los elementos de entrada requeridos:
- estado del trabajo:El trabajo es estado.
- motivo del fracaso laboral:Si el trabajo falló, el motivo del fallo.
- métricas de ejecución:Información sobre los documentos procesados por el trabajo. Se incluyen las siguientes métricas:
- CREADO CON ÉXITO:El número de documentos creados exitosamente.
- ACTUALIZADO EXITOSAMENTE:El número de documentos actualizados exitosamente.
- SALTADOS COMO DUPLICADOS:La cantidad de documentos omitidos como duplicados.
- FILTRADO:La cantidad de documentos filtrados por un filtro específico de la fuente o un filtro de conector.
- MAL REGISTRO:La cantidad de interacciones digitales enviadas para procesamiento que no coincidían con el formato conversacional de Qualtrics .
- NO SE OBSERVÓ ACCIÓN:La cantidad de documentos omitidos por no ser duplicados.
- ERROR AL CARGAR:La cantidad de documentos que no se pudieron cargar.
- TOTAL:El número total de documentos procesados durante la ejecución de este trabajo.
Mensajes de error
Los siguientes mensajes de error son posibles para la solicitud de API de estado:
- 401 No autorizado:La autenticación falló. Utilice una clave API diferente.
- 404 No encontrado:No existe un trabajo con el ID especificado. Utilice un ID de trabajo diferente.
Solicitud de Muestra
A continuación se muestra un ejemplo de solicitud para obtener el estado de un trabajo:
curl --ubicación --solicitud OBTENER 'https://na-data.clarabridge.net/v1/public/job/status/62da736987c9788b830918e0?apiKey=02e7a0e26b592632dd50f623e974fff6'
Respuesta de Muestra
A continuación se muestra un muestra de respuesta de un trabajo fallido:
{
"job_status": "Error",
"job_failure_reason": "{\"problem\":[{\"requestId": "RQ-MOB-f339aa58-71b6-4a1d-a67c-12b8d3439321", "severity": "ERROR", "description": "Se ha excedido el límite de longitud de 900 caracteres para el atributo supportexperienceresp, la longitud es 1043"}], "status": "ERROR"}",
"métricas_de_ejecución": {
"creado exitosamente": 10,
"Error al cargar": 1,
"total": 11
}
}
Ejemplos de carga útil
Esta sección contiene 1 ejemplo de carga útil JSON para cada tipo de datos estructurados admitido (opinión, chat, llamada).
- Haga clic aquí para ver el ejemplo de carga útil de opinión .
curl --ubicación --solicitud POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4e583f9142ae48a1090a76' \
--header 'Tipo de contenido: aplicación/ json' \
--datos-raw '{
"dataSource": " JSON estándar",
"ID de fila": "id43682",
"numero_tienda": "226,1,1,0,0",
"dirección": "5916 W Loop 289 Lubbock, TX 79424",
"número_de_teléfono": "806-791-4384",
"nombre_revisor": "Mariposa",
"calificación de revisión": 2,
"Fecha de revisión": "03.03.2019",
"Conocimientos del empleado": 2,
"Precio_valor": 3,
"Proceso de pago": 1,
"comentarios": "Una de las mejores experiencias que he tenido en Best Buy en mucho tiempo. "Sigan con el buen trabajo.",
"LTR": 10,
"estado": "TX",
"Miembro de recompensas": "MyBestBuy"
}'
- Haga clic aquí para ver el ejemplo de carga útil del chat.
curl --ubicación --solicitud POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4d77656afa99b0396ef959' \
--header 'Tipo de contenido: aplicación/ json' \
--datos-raw '{
"conversationId": "37854",
"conversationTimestamp": "2020-07-30T12:42:15.000Z",
"contenido": {
"tipoContenido": "CHAT",
"participantes": [
{
"participanteId": "1",
"participantType": "AGENTE",
"is_bot": verdadero
},
{
"participanteId": "2",
"participantType": "CLIENTE",
"is_bot": falso
}
],
"conversaciónContenido": [
{
"participanteId": "1",
"text": "Hola, ¿en qué puedo ayudarle?",
"marca de tiempo": "2020-07-30T12:42:15.000Z",
"id": "3785201"
},
{
"participanteId": "2",
"text": "Hola, ¿estás abierto hoy?",
"marca de tiempo": "2020-07-30T12:42:15.000Z",
"id": "3785202"
},
{
"participanteId": "1",
"text": "Estamos abiertos desde las 17:00 hasta las 23:00.",
"marca de tiempo": "2020-07-30T12:42:15.000Z",
"id": "3785203"
},
{
"participanteId": "2",
"texto": "Me gustaría hacer una reserva.",
"marca de tiempo": "2020-07-30T12:42:15.000Z",
"id": "3785204"
},
{
"participanteId": "1",
"texto": "¡Por supuesto! ¿Qué nombre puedo utilizar?",
"marca de tiempo": "2020-07-30T12:42:15.000Z",
"id": "3785205"
}
]
},
"ciudad": "Boston",
"fuente": "Facebook"
}'
- Haga clic aquí para ver la carga útil del ejemplo de llamada.
curl --ubicación --solicitud POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4e564d9242ae6e6308ff04' \
--header 'Tipo de contenido: aplicación/ json' \
--datos-raw '{
"conversationId": "462896",
"conversationTimestamp": "2020-07-30T10:15:45.000Z",
"contenido": {
"contentType": "LLAMADA",
"participantes": [
{
"participante_id": "1",
"tipo": "AGENTE",
"is_ivr": falso
},
{
"participante_id": "2",
"tipo": "CLIENTE",
"is_ivr": falso
}
],
"conversaciónContenido": [
{
"participante_id": "1",
"texto": "Soy Emily, ¿en qué puedo ayudarle?",
"inicio": 22000,
"fin": 32000
},
{
"participante_id": "2",
"texto": "Hola, tengo un par de preguntas.",
"inicio": 32000,
"fin": 42000
}
],
"contentSegmentType": "GIRAR"
},
"ciudad": "Boston",
"fuente": "Centro de llamadas"
}'