インポート(EX)する参加者ファイルの準備
このページの内容
Qtip:このページの最初のセクションでは、エンゲージメント、ライフサイクル、パルス、およびアドホック従業員調査プロジェクトに参加者をアップロードするためのファイル要件について説明します。ただし、このページの残りの部分では、階層固有のファイル要件についても説明しており、これらはライフサイクルやアドホック従業員ライフサイクル調査には適用されないことを覚えておいてください。それぞれの詳細については、「Employee Experienceプロジェクトのタイプ」を参照してください。
参加者ファイルの作成について
従業員エクスペリエンス プロジェクトに参加者をインポートする際には、いくつかの重要な点に留意する必要があります。例えば、すべての参加者のインポートには、階層タイプに関係なく、以下の列が必要です:
- ファーストネーム:従業員のファーストネーム。
- 姓:従業員の姓。
- 電子メール従業員のEメールアドレス。このディテールが最も重要だ。電子メールは、参加者ごとのユーザー名として、またはディレクトリにすでに存在するユーザーを記憶する方法として機能します。 注意: 参加者ファイルのEメールフィールドが空白のままになっている場合、UniqueID@BrandID.fake という書式をプレースホルダとして使用した人工Eメールが生成され、個人情報が補完されます。生成されたEメールは人工的なものであるため、Eメールが有効なアドレスに更新されるまで、参加者にEX配信は行われません。しかしだ、 組織がSSOを導入している場合、検証用メールアドレスを含める必要があります。 参加者をアップロードする際に、正しいユーザー名が自動生成されるようにします。

- UniqueIdentifier:参加者を任意の識別子で指定します。社内の数値IDからユーザー名、EmployeeIDカラムの繰り返しまで、何でも使用できます(ただし、組織内で一意であり、他のプロジェクトの誰とも共有されない場合に限ります)。詳しくはUnique Identifiersのサポートページをご覧ください。
Qtip:組織にSSOがある場合、プロジェクトに参加者をアップロードする前に、UserNameの列がSSOのユーザー名属性と一致するように、ディレクトリに参加者をアップロードしてください。
Qtip:SMS を使用して EX アンケートを配信する場合は、電話番号または電話という名前の列を追加し、電話番号の書式設定ルールに従います。
Engagementプロジェクトを作成する場合、CSV/TSVファイルに含めるメタデータ(参加者データのカスタム列)に影響するため、プロジェクトに適切な階層を選択していることを確認する必要があります。例えば、親子階層ファイルには従業員IDとマネージャーIDのカラムを含める必要がありますが、レベルベース階層ファイルには異なるレベルのカラムを含める必要があります。このページでは、各階層に含めるべきメタデータについて説明する。
Qtip:プロジェクト内に複数の階層を持つことができますが、各メタデータ・フィールドは1つの階層を生成するためにのみ使用できます。例えば、”ManagerID “を使用して最初の階層を構築した場合、同じフィールドを使用して2つ目の階層を構築することはできません。
そもそも正しいメタデータを入れ忘れたとしても、それはそれで構わない!リンク先のセクションの手順に従って、参加者のメタデータを後からいつでも更新することができます。
Qtip:ファイルをアップロードする準備はできているが、方法がわからない?このページの指示に従って階層ファイルを設定したら、参加者の追加サポートページにアクセスしてください。
Qtip:どのような階層が貴社のHRデータに最も適しているのか、お分かりになりませんか?階層の基本概要ページで、オプションの基本比較をご確認ください。
親子階層の参加者のインポート
親-子階層は最もよく使われる階層である。従業員のIDと各従業員がレポートするマネージャーのリストがあるように、人事データがフォーマットされている場合は、これらのオプションが最適です。
ここをクリックして、親子階層のテンプレートにアクセスします。
必要なメタデータ
親子階層を作成するには、2つのメタデータカラムを含める必要があります:
- 従業員ID:参加者の従業員IDです。新しくランダム化されたIDを作ろうとするのではなく、会社の人事部が社内で割り当てたIDを使うのがベストです。
- マネージャーID:これは参加者のマネージャーの従業員IDです。
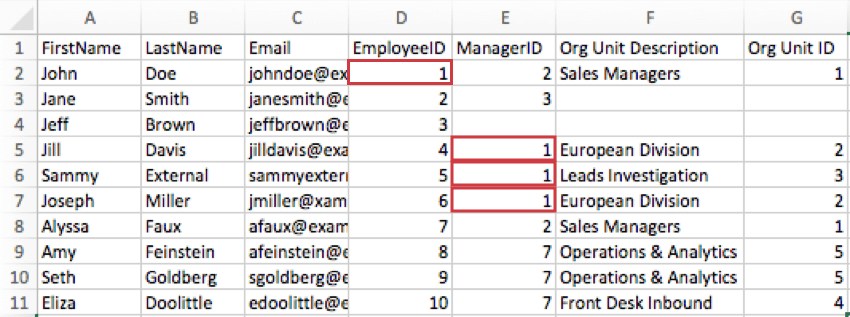
例: 以下の画像では、John DoeのEmployeeIDは1であるため、彼のEmployeeIDカラムは1となります。Jill Davis、Sammy External、およびJoseph MillerはJohn Doeの直属の部下であるため、ManagerID列には1が表示されます。
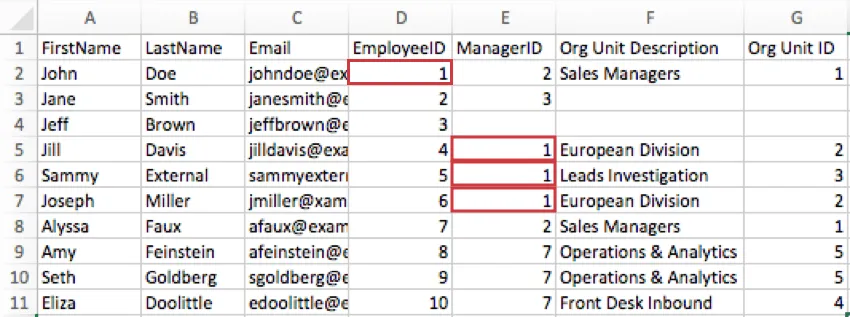
Qtip: 技術的には、EmployeeIDとManagerIDに好きな名前を付けることができます。例えば、あなたの組織が「従業員番号」という言葉を好んだり、「QID」のような特別な言葉を使ったりする場合は、自由にこれらの名前を列につけてください。重要なのは、親子階層を作成する際に、これらの概念を含め、正しいフィールドに入力することです。
従業員IDやマネージャーIDを追加する際には、いくつか注意すべき点があります:
- データの一意識別子列は、親子階層を生成する際に従業員IDフィールドに使用できます。その場合、先の例はどうなるかというと、こうなる:

- また、参加者は全員、固有の従業員IDを持っていなければならない。複数の参加者が同じIDを共有することはできません。これは固有識別子と同じにすることができる。
- 参加者には必ずマネージャーが必要だ。唯一の例外は、階層に含める企業の最上位メンバー(CEOなど)である。マネージャー欄は空欄にし、この人物が誰にもレポートされていないことを示す。
- 個々の従業員の従業員IDとマネージャーIDの列は決して同じであってはならない。従業員は自分自身に報告しない!
- すべてのマネージャーIDは従業員にリンクしていなければなりません。既存の従業員IDに対応しないマネージャーIDを持つ参加者は、不明マネージャーに割り当てられます。不明マネージャーに誰かが割り当てられると、その下の階層のメンバーも壊れることに注意してください。この問題を解決するには、手動でデータを修正し、階層を再生成する必要がある。
- 循環論理に気をつけよう。ジョン・ドウがジェーン・スミスにレポートし、ジェーン・スミスがジョセフ・ミラーにレポートする場合、ジョセフ・ミラーがジョン・ドウにレポートすることはできない。マネージャーのマネージャーを管理することはできない。
オプションのメタデータ
参加者リストをアップロードする際に、ご希望のメタデータを追加することができます。各従業員の誕生日からオフィスの所在地まで、何でも記載することができる。しかし、親子階層をフォーマットするのに役立つオプションのメタデータが2つあります。
- 組織ユニットID:組織ユニットIDは、チーム名が変わっても、同じチームを識別するのに役立ちます。ITは、従業員ではなくユニットに対して一意の従業員IDと同じ目的を果たす。安定した組織階層の特定ユニットIDを含めることは、階層データを手作業でマッピングする必要がないことを意味します; システムはIDを認識し、適切にマッピングします。マネージャーが複数のチームを統括している場合にも、Org Unit IDは役に立つ。つまり、マネージャーがJohn Doeで、John DoeがチームAとチームBのマネージャーである場合、直属の部下がどのチームに帰属するかをUnit IDフィールドで指定することができます。
- 組織単位の説明:階層を作成する際、ユニットにはマネージャーの名前が自動的に付けられます。Org Unit Descriptionの設定では、代わりにユニットの名前や説明に基づいてユニット名を付けることができます。 Qtip: 組織単位のレポートは、マネージャーではなく、直属の部下からの情報に基づいて作成されます。

Org Unit Descriptionは、特定のOrg Unit IDの名前として機能し、ダッシュボードでユニットごとにフィルターやブレイクアウトを行う際に、ユニットのラベルとして表示されます。例えば、組織ID2の組織単位の説明は欧州部署である。 各ユニットIDに対してユニット説明は1つしか存在できず、その逆も同様である。同様に、従業員が同じ組織単位に帰属している場合、その説明も一致させる必要がある。
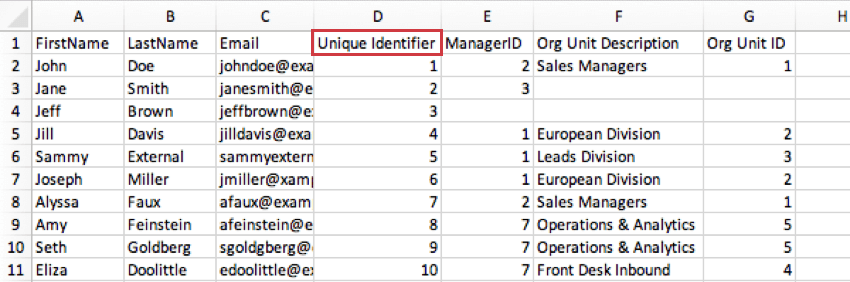
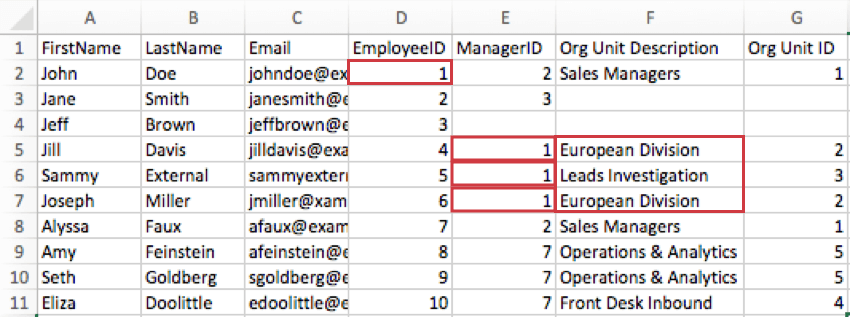
例: 下の画像では、ジョン・ドウは2つの異なるチームをマネージャーしています:ヨーロッパ部署とリード調査です。Org Unit Descriptionの欄には、直属の部下3人がどのチームに帰属しているかが明記されている。ジル・デイビスとジョセフ・ミラーはヨーロッパ部署にいるが、サミー・エクスターナルはリード捜査部にいる。

例: 下の画像では、ジルとジョセフはともに「ヨーロッパ部署」に帰属し、部署IDは2である。

Qtip: 技術的には、Org Unit IDとOrg Unit Descriptionフィールド名には好きな名前をつけることができます。例えば、Org Unit Descriptionの代わりに、Unit Name、Team、Departmentといったカラム名を付けることができます。重要なのは、親子階層を作成する際に、これらの概念を含め、正しいフィールドに入力することです。
階層ベースの参加者のインポート
階層ベースの階層は、従業員がレポートする各レベル(階層の最上位から最下位まで)が人事データに含まれている場合に適しています。レベルベースの階層では、必ずしも従業員のマネージャーを知る必要はなく、プロジェクトに参加させる各従業員の指揮命令系統を知るだけでよい。このデータ形式は、従業員データをレベル別、勤務地別、詳細区分別に整理している企業でよく見られます。
ここをクリックして、レベルに基づく階層のテンプレートにアクセスします。
例: 階層は、各参加者がダッシュボードでどのデータを見ることができるかを管理することができます。例えば、異なる場所にある店舗で会社の賞品を争うとして、参加者が自分のダッシュボードを見ることはできても、お互いのダッシュボードを見ることはできないとします。ロケーションに基づいて階層を構築すると、後でダッシュボードのロールを構築したり、ダッシュボードのユーザー権限を設定したりするときに、各参加者がどのロケーションのデータを見るかを制限することができます。
必要なメタデータ
定義したい組織のレベルごとに別の列が必要です。参加者の最後に記入されたレベルは、階層におけるその人の位置を示す。上位の選手にとって、これは通常、最初のレベル欄は埋まっているが、残りは埋まっていないことを意味する。
例: あなたの会社が全米に拠点を持っているとします。レベル1には、あなたのオフィスがあるすべての州が含まれるかもしれません。そしてレベル2は、これらのオフィスがある都市となる。つまり、テキサス州ダラスのオフィスの参加者は、レベル1がテキサス、レベル2がダラスとなる。テキサスがレベル1の参加者は、ヒューストンがレベル2かもしれない。
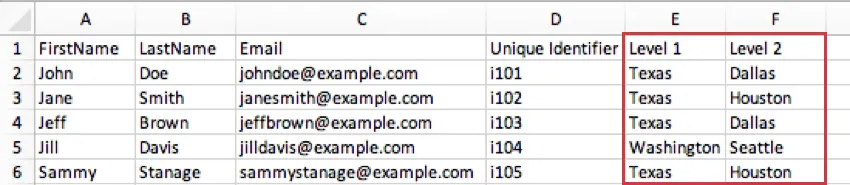
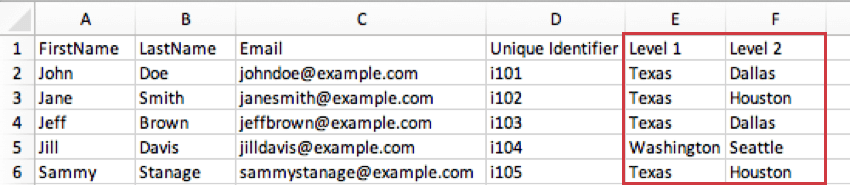
Qtip: 技術的には、これらのメタデータ・カラムに好きな名前をつけることができる。例えば、階層を場所に基づいて作成する場合、レベル1、レベル2、レベル3の代わりに、Country、State/Region、Cityという名前のカラムを持つことができます。重要なのは、レベルベースの階層を作成する際に、これらの概念を含め、正しいフィールドに入力することです。
マネージャー メタデータ
レベル階層内のユニットにマネージャーを割り当てるには、2つの方法があります。
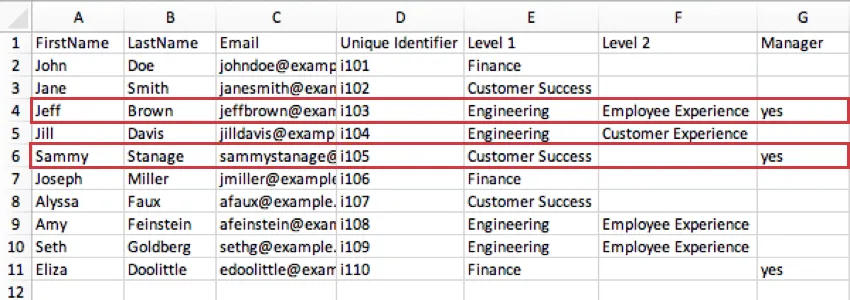
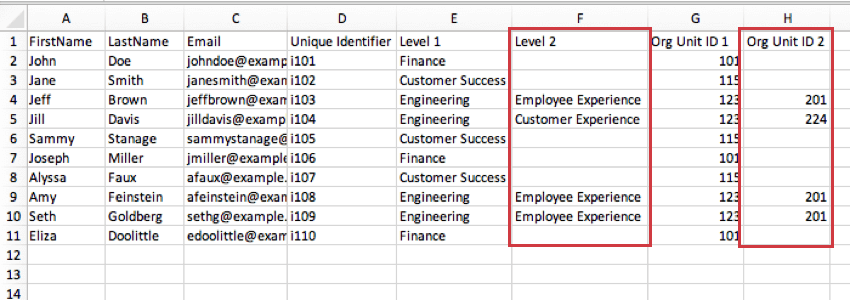
- マネージャー:この欄は、参加者がマネージャーであるかどうかを示す。参加者は、自分が一覧表示した最下位レベルのマネージャーとして割り当てられます。ほとんどのユーザーは、マネージャーであることを示すために「はい」を使用しますが、参加者がマネージャーであることを示す列の値が1つであれば、「1」、「マネージャー」、または任意の形式を使用することもできます。 例: 下の画像では、Sammy Stanageの最低レベルはレベル1で、カスタマーサクセスの役割に就いています。マネージャー欄の「はい」は、カスタマーサクセス全体のマネージャーであることを示している。一方、ジェフ・ブラウンが最後に定義したレベルは、エンジニアリング部門の従業員エクスペリエンスである。つまり、エンジニアリングの中では従業員エクスペリエンスレベルの責任者ということになる。

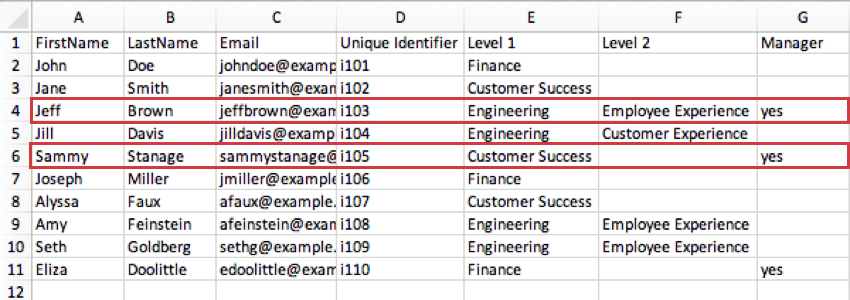
- マネージャーレベル:マネージャーレベルとは、マネージャーを識別するための手段であり、そのマネージャーが管理する特定のレベルを示すものである。前の例では、同じ値(“yes”)は参加者がマネージャーであるかどうかを示しますが、マネージャーレベルでは、レベルごとに別々の値があります。 例: 下の画像では、ジェフ・ブラウンのマネージャーレベルが「2」になっています。これは、ジェフが「エンジニアリング」のレベル1のポジションのマネージャーではなく、「従業員エクスペリエンス」のレベル2のポジションのマネージャーであることを示しています。

オプションのメタデータ
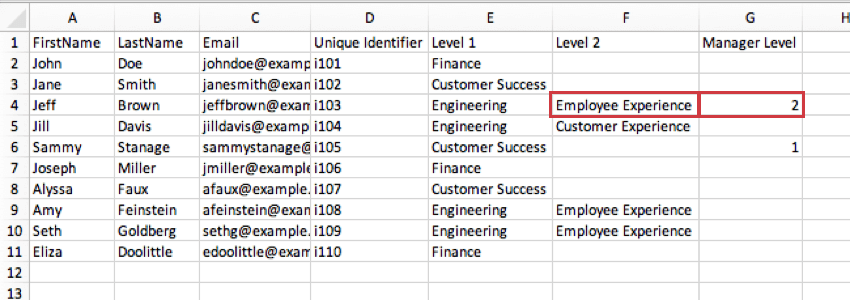
組織ユニットID:組織ユニットIDは、チーム名が変わっても、同じチームを識別するのに役立ちます。安定した組織階層の特定ユニットIDを含めることは、階層データを手作業でマッピングする必要がないことを意味します; システムはIDを認識し、適切にマッピングします。ITは、従業員ではなくユニットに対して一意の従業員IDと同じ目的を果たす。レベルと同数の組織単位IDを含める必要があるため、各レベルにIDを提供できます。
組織階層の階層ごとに、一意な組織階層の特定ユニットID列がなければならない。例えば、組織に “レベル1 “と “レベル2 “の2つのレベルがある場合、組織ユニットID用に2つの列が必要になります:組織単位IDには2つの列が必要である。”組織単位ID 1 “はレベル1に属する者の組織単位IDを含み、”組織単位ID 2 “はレベル2に属する者の組織単位IDを含む。また、組織単位のフィールド名を再利用しないように注意しなければなりません。これが番号付けを推奨する理由です。
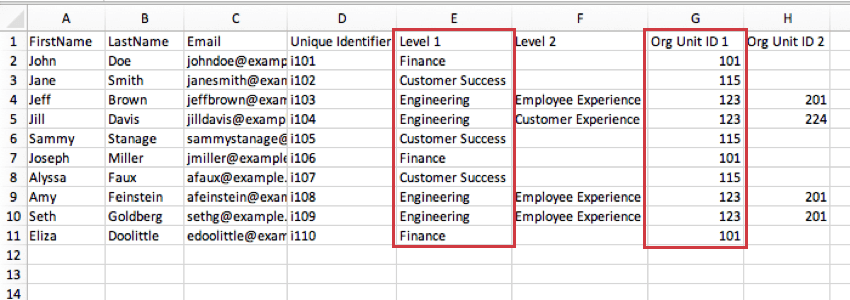
例: レベル1のユニットはOrg Unit ID 1の列に対応する。Financeはユニット101、Engineeringは123など。もし次年度に階層をアップロードし、FinanceをThe Penny Patrolに改名した場合、ダッシュボードで複数年分のengageデータをレポートするために階層データを手作業でマッピングする必要がないように、同じID、101を与えることになる。

以下のスクリーンショットでは、レベル 2 のユニットが Org Unit ID 2 列に対応しています。従業員エクスペリエンス・エンジニアリングチームはユニット201で、カスタマーエクスペリエンス・エンジニアリングチームは224です。

{kind=link}
{kind=link}
{kind=link}
スケルトン階層の参加者のインポート
スケルトン階層は、マネージャーの身元はわかっているが、直属の部下がわからない場合に使用する。直属の部下とその上の指揮命令系統のリストを中心に階層を組織するのではなく、マネージャーと彼らがロールアップするユニットのリストを構築するのだ。スケルトン階層の例を
以下に示す。CSV/TSVを作成し、各マネージャーの行を作成する。スケルトン階層を構築するには、少なくともマネージャー情報が必要だ。
マネージャーごとに、マネージャーのファーストネーム、 ラストネーム、 Eメール、、その他入れたいメタデータの列を追加する。次に、以下のメタデータを追加する必要がある:
- 従業員ID: 従業員が管理するユニットのID。
- マネージャーID:このユニットの直上のユニットのID。従業員がレポートする部署です。
- 組織の説明:このメタデータはオプションである。従業員が管理するユニットの名前を作成することができます。これはチーム名でもいいし、マネージャーの名前でもいい。
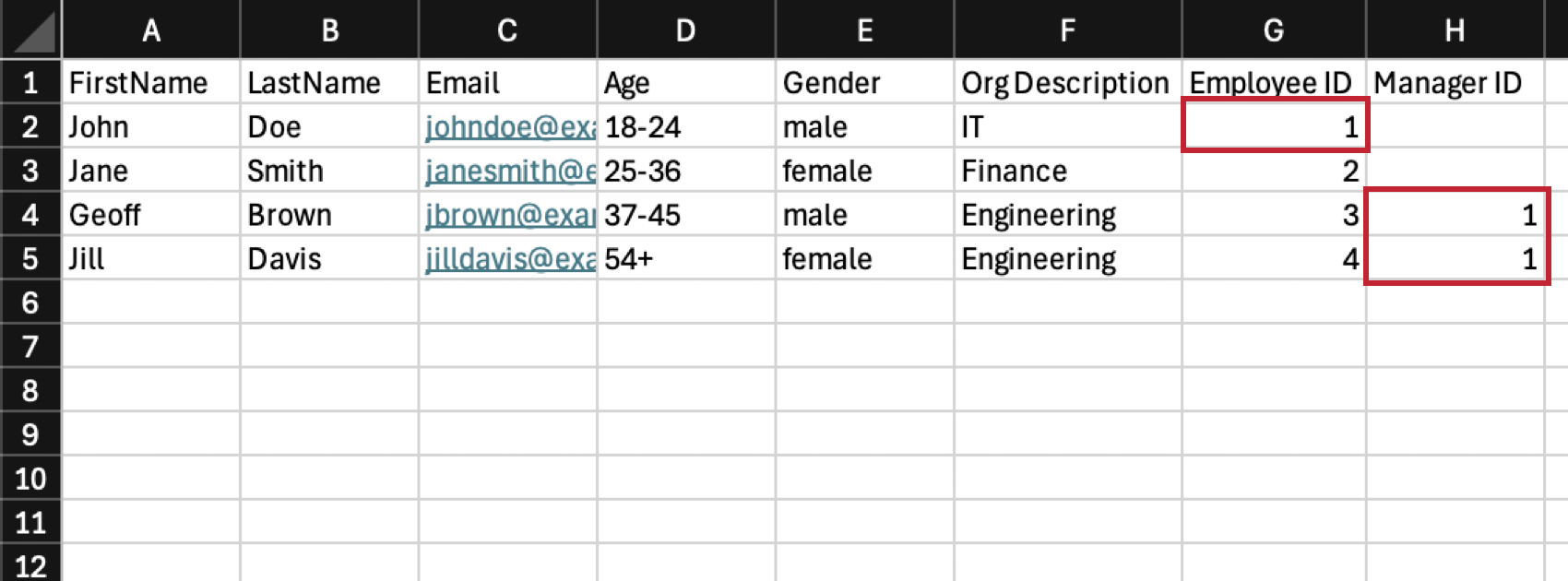
例: 以下の例では、IT部門はより大きな部門であり、エンジニアリング部門はその下にネストされている。Geoff BrownとJill DavisはEngineeringのマネージャーなので、2人ともマネージャーIDは1であり、ITがEngineeringの親ユニットであることを示している。

{kind=link}
Qtip: 参加者ファイルはすでにインポートされていますか?階層生成の詳細については、親子階層の生成のサポートページをご覧ください。
回答者vs. 未回答者
回答者とは、アンケートに答えてくれる参加者のことです。無回答者とは、アンケートにアクセスできない参加者のことです。ダッシュボードの結果や組織階層の確認はさせたいが、アンケートに回答してほしくない参加者を無回答者にすると便利です。
Qtip:参加状況の概要と回答率のウィジェットでは、回答者のみがカウントされます。
追加する参加者がプロジェクトの回答者であるかどうかは、Respondentというヘッダーを含め、次の値のいずれかを使用することで判断できます:
- 0 – 無回答
- 1 – 回答者
ファイルに回答者の列を含めない場合、新しい参加者はデフォルトですべて回答者に設定されます。すでにプロジェクトに参加している人がいる場合、その人のステータスは指定されたときだけ更新されます。
Qtip:参加者セクションの検索を使用して、プロジェクトの回答者を見つけることができます。
Qtip:参加者情報ウィンドウで、個々の参加者が回答者であるかどうかを調整することができます。
最大文字数とサポート文字数
警告: すべてのメタデータフィールドは、以前はフィールド名にスペーシングを認識していました。大多数のユーザーにとって、メタデータのフィールド名はスペースを無視するようになりました。つまり、参加者ファイルをインポートする際、「マネージャーID」と「マネージャーID」は同じフィールドとして扱われます。
警告: メタデータフィールドに、予約済みの埋め込みデータフィールドと同じ名前をつけないでください。これらのフィールドでは、大文字と小文字が区別されません。
各フィールドの最大文字数
- ファーストネーム50文字
- 名字:各姓50文字。
- Eメール:各メールに100文字
- 一意識別子:一意識別子ごとに100文字。
- その他すべてのメタデータ:メタデータ名は90文字まで、値は1000文字まで。
部分的にサポートされている文字
注意: 参加者インポーターではこれらの文字をインポートできる場合がありますが、クアルトリクス・プラットフォームのさまざまな部分でエラーを引き起こす可能性があるため、可能な限り避けることをお勧めします。
以下の文字は、メタデータの名前や値に使用しないでください:
|
&
;
$
%
< >
( )
{ }
*
+
、 日付などのフィールドの値にはスラッシュ(/)を使用できますが、メタデータフィールド名には使用できません。
制限付きメタデータフィールド名
参加者ファイルにこれらのフィールド名または接頭辞が含まれている場合、これらのフィールドはインポートされず、データはスキップされます。
以下のメタデータフィールド名は使用できない:
finished
q_units
sid
responsesetid
rid
threesixtyid
enddate
auditable
personid
_cacheddate
userid
_recordid
firstname
_recordeddate
_enddate
email
_startdate
userpassword
_sourceid
password
_sourcemapid
external
_sourcetype
q_primaryunits
uniqueid
uniqueidentifier
loginname以下の接頭辞はメタデータフィールド名には使用できない:
ステートメント
raw_statement
_FAQs
すでに参加者ファイルをアップロードし、データを収集しましたが、階層を変更する必要があります。どうすればいいのでしょうか?
すでに参加者ファイルをアップロードし、データを収集しましたが、階層を変更する必要があります。どうすればいいのでしょうか?
親子階層を設定する際、階層単位にマネージャー名を割り当てるのではなく、ユニット名を使用するようにしたい。どうすればいいのでしょうか?
親子階層を設定する際、階層単位にマネージャー名を割り当てるのではなく、ユニット名を使用するようにしたい。どうすればいいのでしょうか?
参加者リストをアップロードして、親子階層を生成しました。"Circular Dependencies "というエラーメッセージが表示されました。なぜこのメッセージが表示されたのか、どうすれば直るのか。
参加者リストをアップロードして、親子階層を生成しました。"Circular Dependencies "というエラーメッセージが表示されました。なぜこのメッセージが表示されたのか、どうすれば直るのか。
参加者リストをアップロードして、親子階層を生成しました。Unknown Manager "と表示されたユニットがあるのはなぜですか?
参加者リストをアップロードして、親子階層を生成しました。Unknown Manager "と表示されたユニットがあるのはなぜですか?
従業員をディレクトリにアップロードしているのですが、私の組織にはSSOがあります。UserNameカラムをフォーマットするには?
従業員をディレクトリにアップロードしているのですが、私の組織にはSSOがあります。UserNameカラムをフォーマットするには?
参加者のユーザー名にSSOサフィックス(#brandID)を含めないようにしてください。 Qualtricsは、すべてのユーザー名に自動的にサフィックスを追加します。SSOサフィックスを含めると、Qualtricsは2回目のサフィックスを追加します。
プロジェクトで使用できる最大階層数は?
プロジェクトで使用できる最大階層数は?
同じプロジェクトで、同じメタデータフィールドを使って複数の組織階層を構築することはできますか?
同じプロジェクトで、同じメタデータフィールドを使って複数の組織階層を構築することはできますか?
その代わり、構築したい階層ごとに異なるフィールドを用意することをお勧めします。たとえば、すべての参加者にUniqueIdentifierとManager IDという列だけを含めるのではなく、EmployeeID2とManagerID2という列も含めて、2つ目の別の階層を構築するのに使用することができます。
CSV/TSVファイルに先頭のゼロが含まれるようにするにはどうしたらいいですか?
CSV/TSVファイルに先頭のゼロが含まれるようにするにはどうしたらいいですか?
ありがたいことに、先頭のゼロが削除されないようにするための解決策があります。 このフォーマットをファイルに追加した場合、Qualtricsにインポートする前に、CSVを開き直さないと、フォーマットが失われる可能性がありますので、ご注意ください。
Can you set whether someone is a respondent (or non-respondent) in the employee directory?
Can you set whether someone is a respondent (or non-respondent) in the employee directory?
素晴らしい! フィードバックありがとうございます!
フィードバックありがとうございます!