-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
XM Discover-Link – Eingangskonnektor
Informationen zum XM Discover Link Inbound Connector
Sie können den XM Discover Link Inbound Connector verwenden, um XM-Daten über einen REST-API-Endpunkt an XM Discover zu senden, während Sie alle Funktionen des Connectors-Frameworks nutzen, z.B. Feldzuordnung, Transformationen, Filter, Jobüberwachung usw.
Unterstützte Datenformate
Die folgenden Datentypen werden nur im JSON-Format unterstützt:
- Individuelles Feedback
- Digitale Interaktionen
- Abrufprotokolle
Bevor Sie den Connector einrichten, legen Sie eine Beispieldatei an, die die Felder darstellt, die Sie in XM Discover importieren möchten. Weitere Informationen zu den erforderlichen Feldern und Dateiformaten finden Sie oben auf den verlinkten Seiten.
Es stehen auch Template-Dateien zum Herunterladen innerhalb des Connectors für bestimmte Datenformate zur Verfügung:
- Chat
- Chat (Standard): Für standardmäßige digitale Interaktionsdaten verwenden.
- Amazon Connect: Verwendung für digitale Interaktionen speziell für Amazon Connect Chat.
- Anruf
- Aufruf (Default): Verwendung für Standard-Anrufprotokolldaten.
- Verint: Verwendung für Verint-spezifische Anrufprotokolle
- Feedback
- Dynamics 365: Verwendung für Microsoft Dynamics-Daten.
Anlegen eines eingehenden XM-Discover-Link-Connector-Jobs
- Klicken Sie auf der Registerkarte Jobs auf Neuer Job.
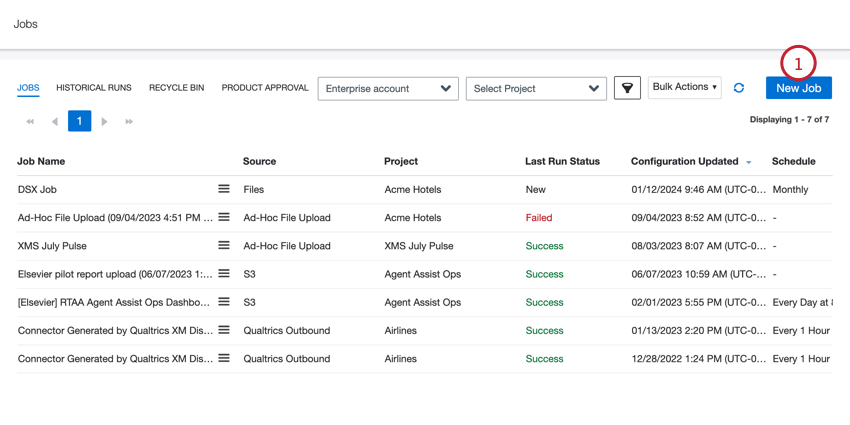
- Klicken Sie auf den Job XM Discover Link.

- Geben Sie Ihrem Job einen Namen, damit Sie ihn identifizieren können.
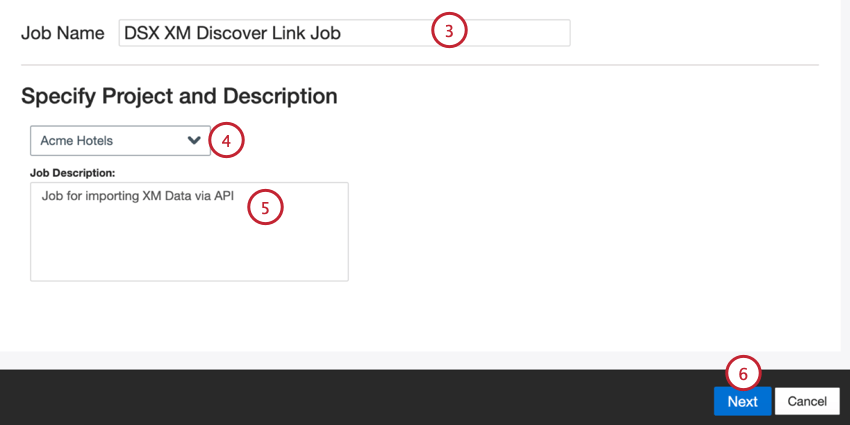
- Wählen Sie das Projekt aus, in das Daten geladen werden sollen.
- Geben Sie Ihrer Stelle eine Beschreibung, damit Sie ihren Zweck kennen.
- Klicken Sie auf Weiter.
- Wählen Sie Ihren Berechtigungsmodus oder wie Sie eine Verbindung zu XM Discover herstellen:
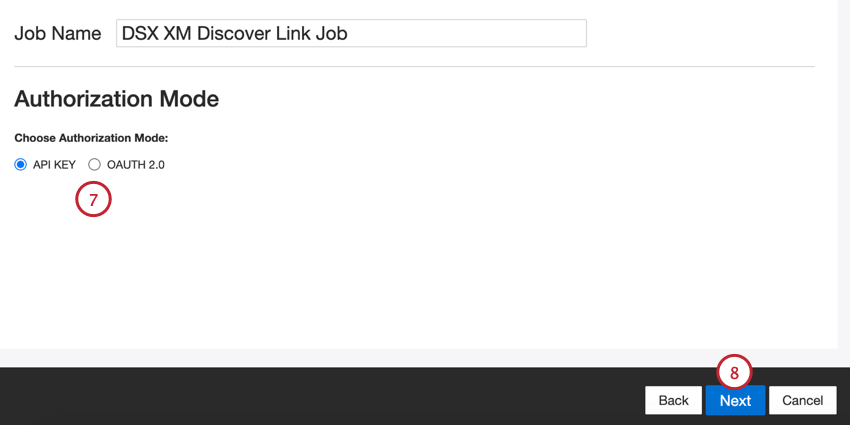
- API-Schlüssel: Stellen Sie eine Verbindung über ein XM-Discover-API-Token her.
- OAuth 2.0: Stellen Sie eine Verbindung über eine Client-ID und einen geheimen Client-Schlüssel her, die vom XM-Discover-Authentifizierungsservice bereitgestellt werden. Wenden Sie sich an Ihren XM Success Manager, um diese Methode anzufordern.
- Klicken Sie auf Weiter.
- Wählen Sie Ihr Datenformat: Chat (digital), Anruf oder Feedback.
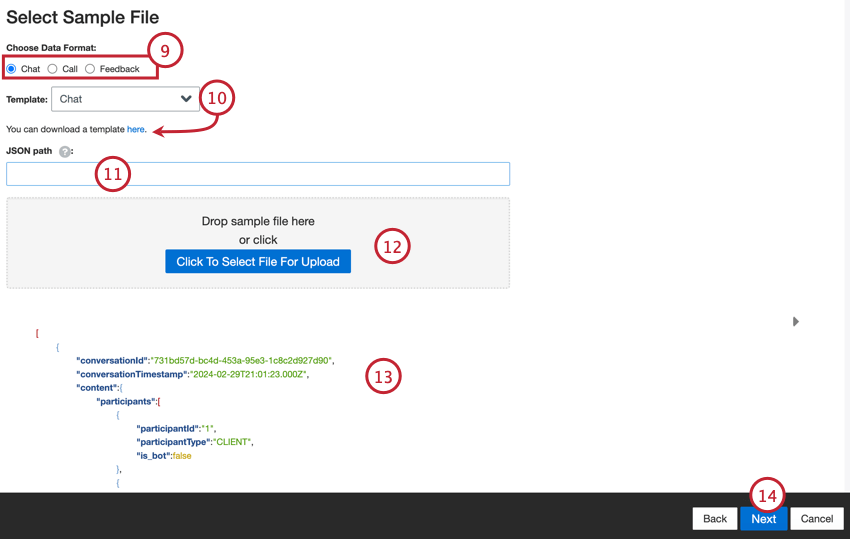
- Wählen Sie bei Bedarf eine Vorlage aus, und klicken Sie dann auf den Link hier, um die Vorlagendatei herunterzuladen.
- Geben Sie den JSON-Pfad zu einer JSON-Teilmenge ein, die Dokumentknoten enthält. Lassen Sie dieses Feld leer, wenn sich die Dokumente auf Wurzelknotenebene befinden.
- Klicken Sie auf die Schaltfläche Klicken, um eine Datei für den Upload auszuwählen, und wählen Sie die Beispieldatei auf Ihrem Computer aus.
- Eine Vorschau der Datei wird angezeigt. Wenn anstelle der Vorschau eine Fehlermeldung oder ein Rohdateiinhalt angezeigt wird, kann es zu Problemen mit den von Ihnen ausgewählten Datenformatoptionen kommen. Auf der Seite “Beispieldateifehler” finden Sie Hilfe bei der Fehlerbehebung für Ihre Datei.
- Klicken Sie auf Weiter.
- Passen Sie bei Bedarf Ihre Datenzuordnungen an. Detaillierte Informationen zur Zuordnung von Feldern in XM Discover finden Sie auf der Supportseite Datenzuordnung. Der Abschnitt Standarddatenzuordnung enthält spezifische Anleitungen für diesen Konnektor.
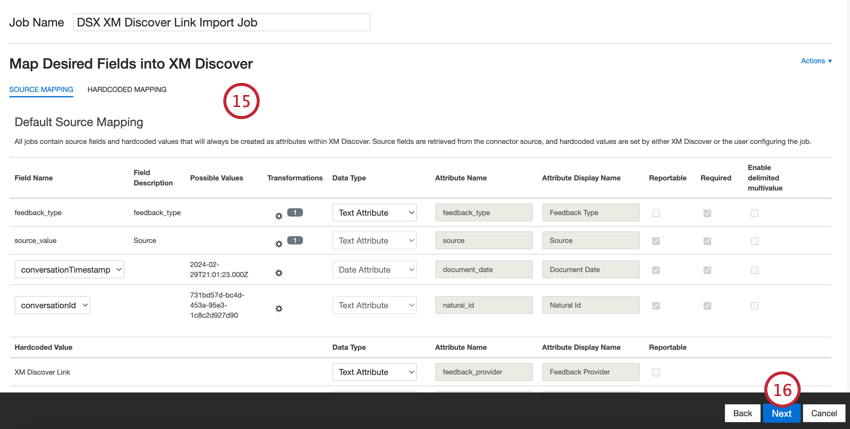
- Klicken Sie auf Weiter.
- Bei Bedarf können Sie Regeln für die Ersetzung und Unkenntlichmachung von Daten hinzufügen, um sensible Daten auszublenden oder bestimmte Wörter und Phrasen in Kundenfeedback und Interaktionen automatisch zu ersetzen. Weitere Informationen finden Sie auf der folgenden Supportseite: Datenersetzung und Redaktion.
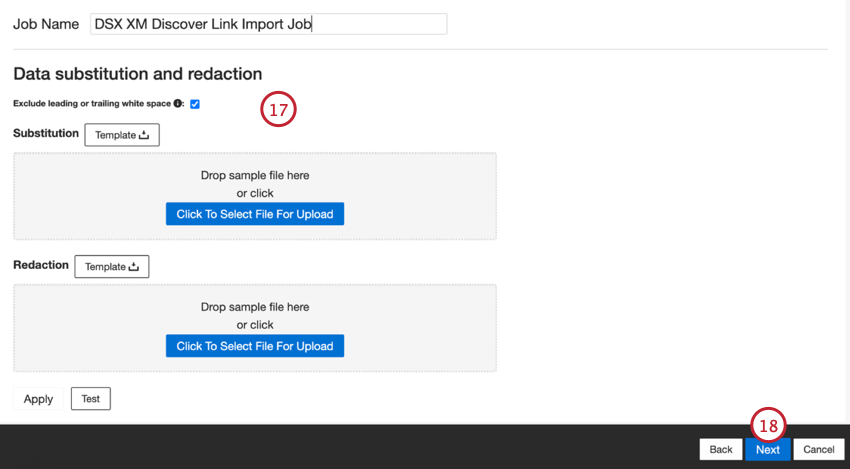
- Klicken Sie auf Weiter.
- Bei Bedarf können Sie einen Konnektorfilter hinzufügen, um die eingehenden Daten zu filtern und so einzuschränken, welche Daten importiert werden.
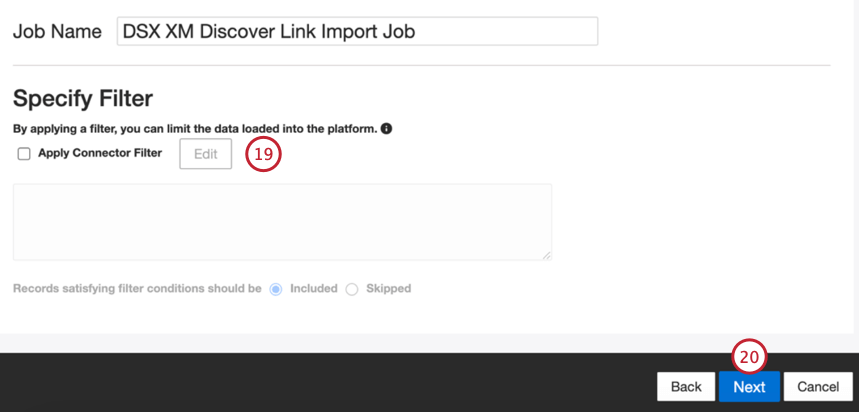
- Klicken Sie auf Weiter.
- Wählen Sie aus, wie doppelte Belege behandelt werden sollen. Weitere Informationen finden Sie unter Behandlung von Duplikaten.
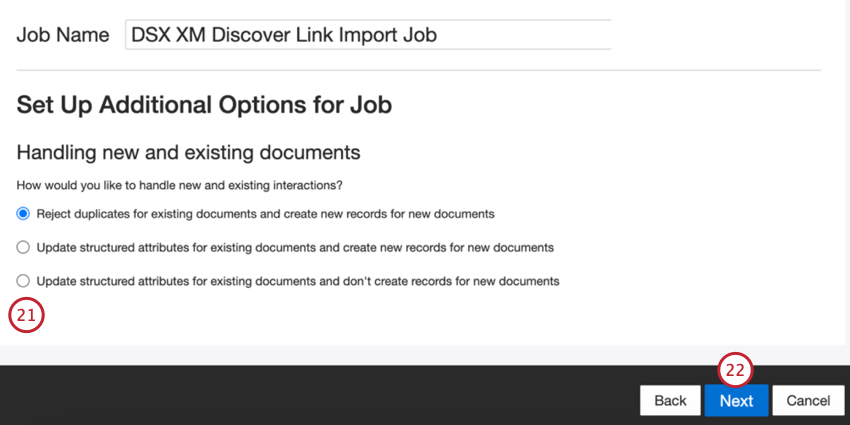
- Klicken Sie auf Weiter.
- Überprüfen Sie Ihre Einrichtung. Wenn Sie eine bestimmte Einstellung ändern müssen, klicken Sie auf die Schaltfläche Bearbeiten, um zu diesem Schritt in der Verbindungseinrichtung zu gelangen.
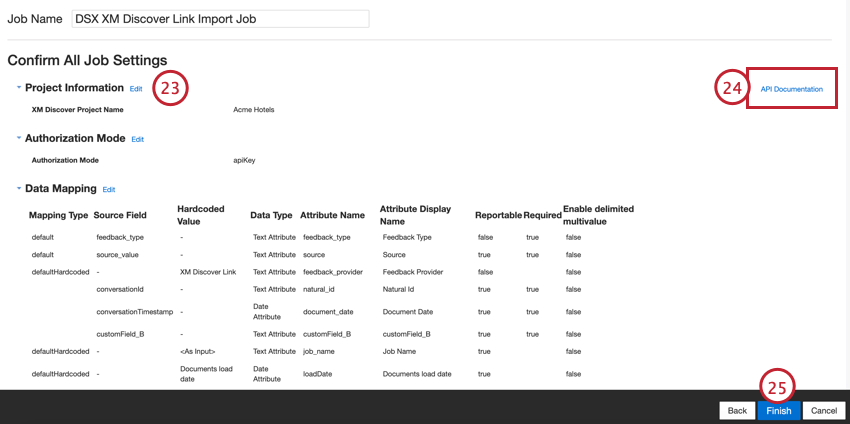
- Der Link API-Dokumentation enthält Ihren API-Endpunkt, der zum Senden von Daten an XM Discover verwendet wird. Weitere Informationen finden Sie unter Zugriff auf den API-Endpunkt.
- Klicken Sie auf Fertig stellen, um Ihre Einrichtung zu sichern.
Standarddatenzuordnung
Dieser Abschnitt enthält Informationen zu den Standardfeldern für XM-Jobs zum Ermitteln eingehender Links.
Beim Zuordnen Ihrer Felder sind die folgenden Standardfelder verfügbar:
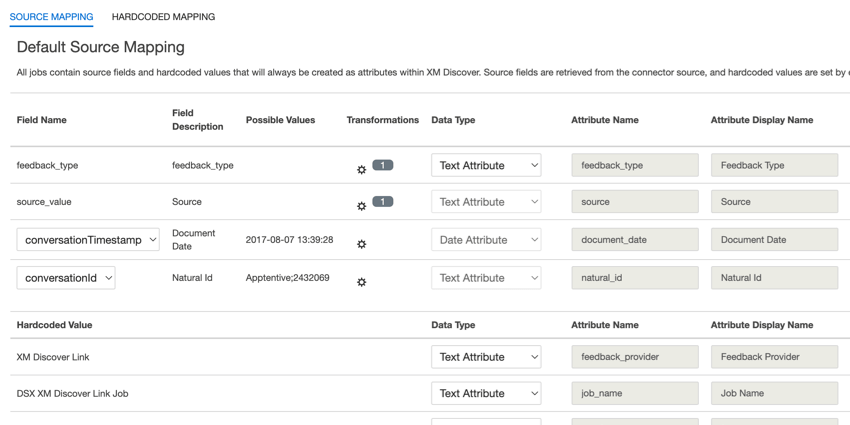
- feedback_type: Mithilfe des Feedback-Typs können Sie Daten anhand ihres Typs identifizieren. Dies ist hilfreich für das Reporting, wenn Ihr Projekt verschiedene Arten von Daten enthält (z.B. Umfragen und Social-Media-Feedback). Dieses Feld kann bearbeitet werden. Standardmäßig ist der Wert dieses Attributs auf Folgendes gesetzt:
- „Call“ für Anrufprotokolle
- „Chat“ für digitale Interaktionen
- „Feedback“ für individuelles Feedback
- Sie können eine benutzerdefinierte Transformation verwenden, um einen benutzerdefinierten Wert festzulegen.
- Quelle: Mit der Quelle können Sie Daten identifizieren, die aus einer bestimmten Quelle abgerufen wurden. Dies kann alles sein, das die Herkunft der Daten beschreibt, z.B. der Name einer Umfrage oder einer mobilen Marketingkampagne. Dieses Feld kann bearbeitet werden. Standardmäßig ist der Wert dieses Attributs auf „XM Discover Link“ gesetzt. Sie können eine benutzerdefinierte Transformation verwenden, um einen benutzerdefinierten Wert festzulegen.
- richVerbatim: Dieses Feld wird für dialogorientierte Daten (wie Anruf- und Chat-Protokolle) verwendet und kann nicht bearbeitet werden. XM Discover verwendet ein dialogorientiertes ausführliches Format für das Feld richVerbatim. Dieses Format unterstützt die Aufnahme dialogspezifischer Metadaten, die zum Entsperren der dialogorientierten Visualisierung (Sprecherwechsel, Stille, Gesprächsereignisse usw.) und Anreicherungen (Startzeit, Dauer usw.) erforderlich sind. Dieses wörtliche Feld enthält „untergeordnete“ Felder, um die Gesprächsseite des Kunden und des Vertreters zu verfolgen:
- clientVerbatim verfolgt die Gesprächsseite des Kunden.
- agentVerbatim verfolgt die Gesprächsseite des Vertreters (Agenten).
- unknown verfolgt die unbekannte Seite des Gesprächs.
-
Tipp: Transformationen werden für sprachbasierte wörtliche Felder nicht unterstützt. Derselbe Wortlaut kann nicht für verschiedene Arten von Konversationsdaten verwendet werden. Wenn Sie möchten, dass Ihr Projekt mehrere Arten von Konversationen hostet, verwenden Sie separate Paare von Gesprächsverben pro Konversationstyp.
- clientVerbatim: Dieses Feld wird für dialogorientierte Daten verwendet und kann bearbeitet werden. Dieses Feld verfolgt die Kundenseite der Konversation in Anruf- und Chat-Interaktionen. Dieses Feld ist standardmäßig zugeordnet zu:
- clientVerbatimChat für digitale Interaktionen.
- clientVerbatimCall für Anrufinteraktionen.
- agentVerbatim: Dieses Feld wird für dialogorientierte Daten verwendet und kann bearbeitet werden. Dieses Feld verfolgt die Seite des Vertreters der Konversation in Anruf- und Chat-Interaktionen. Dieses Feld ist standardmäßig zugeordnet zu:
- agentVerbatimChat für digitale Interaktionen.
- agentVerbatimCall für Anrufinteraktionen.
- unknown: Dieses Feld wird für dialogorientierte Daten verwendet und kann bearbeitet werden. Dieses Feld verfolgt die unbekannte Seite der Konversation in Anruf- und Chat-Interaktionen. Standardmäßig ist dieses Feld Folgendem zugeordnet:
- unbekanntVerbatimChat für digitale Interaktionen.
- unknown wnVerbatimCall für Anrufinteraktionen.
- document_date: Das Belegdatum ist das primäre Datumsfeld, das mit einem Beleg verknüpft ist. Dieses Datum wird in XM-Discover-Berichten, Trends, Warnungen usw. verwendet. Wählen Sie für das Belegdatum eine der folgenden Optionen:
- conversationTimestamp (für Konversationsdaten): Datum und Uhrzeit für die gesamte Konversation.
- Wenn Quelldaten andere Datumsfelder enthalten, können Sie eines davon als Belegdatum festlegen, indem Sie es aus dem Dropdown-Menü im Feld Feldname auswählen.
- Sie können auch ein bestimmtes Datum festlegen, indem Sie ein benutzerdefiniertes Feld hinzufügen.
- natural_id: Natürliche ID dient als eindeutiger Identifikator eines Dokuments und ermöglicht die korrekte Verarbeitung von Duplikaten. Wählen Sie für die natürliche ID eine der folgenden Optionen:
- ConversationId (für Konversationsdaten): Eine eindeutige ID für die gesamte Konversation.
- Wählen Sie einen beliebigen Text oder ein beliebiges numerisches Feld aus Ihren Daten im Feld Feldname aus.
- Generieren Sie automatisch IDs, indem Sie ein benutzerdefiniertes Feld hinzufügen.
- feedback_provider: Der Feedbackanbieter hilft Ihnen dabei, die von einem bestimmten Anbieter erhaltenen Daten zu identifizieren. Für Uploads von XM Discover Link ist der Wert dieses Attributs auf „XM Discover Link“ gesetzt und kann nicht bearbeitet werden.
- job_name: Mit dem Jobnamen können Sie Daten anhand des Namens des Jobs identifizieren, der zum Hochladen verwendet wird. Sie können den Wert dieses Attributs im Feld Jobname oben auf der Seite oder über das Joboptionsmenü ändern.
- loadDate: Ladedatum gibt an, wann ein Dokument in XM Discover hochgeladen wurde. Dieses Feld wird automatisch gesetzt und kann nicht bearbeitet werden.
Zusätzlich zu den oben genannten Feldern können Sie auch alle benutzerdefinierten Felder zuordnen, die Sie importieren möchten. Weitere Informationen zu benutzerdefinierten Feldern finden Sie auf der Supportseite Datenzuordnung.
Zugriff auf den API-Endpunkt
Der API-Endpunkt wird verwendet, um Daten in XM Discover hochzuladen, indem die Daten über eine REST-API-Anforderung im JSON-Format gesendet werden.
Sie können über die Seite Jobs auf den Endpunkt zugreifen:
- Wählen Sie im Joboptionsmenü für Ihren Job die Option Zusammenfassung.
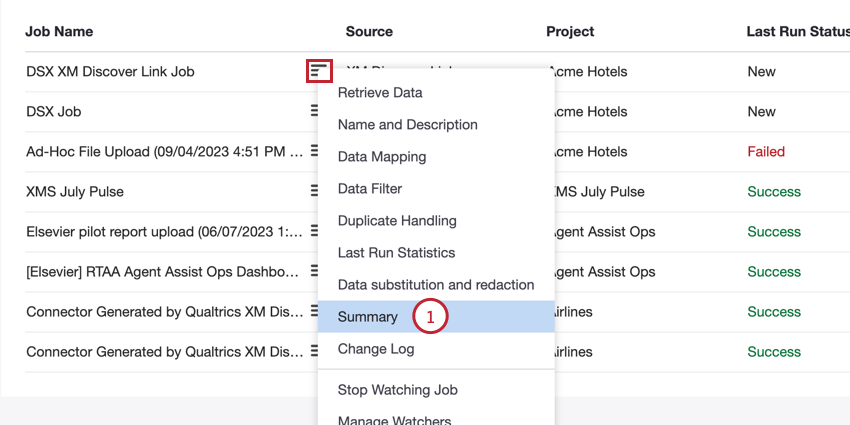
- Klicken Sie auf den Link API-Dokumentation.

- Klicken Sie auf die Schaltfläche Drucken, um alle Informationen in diesem Fenster als druckbare PDF-Datei herunterzuladen.
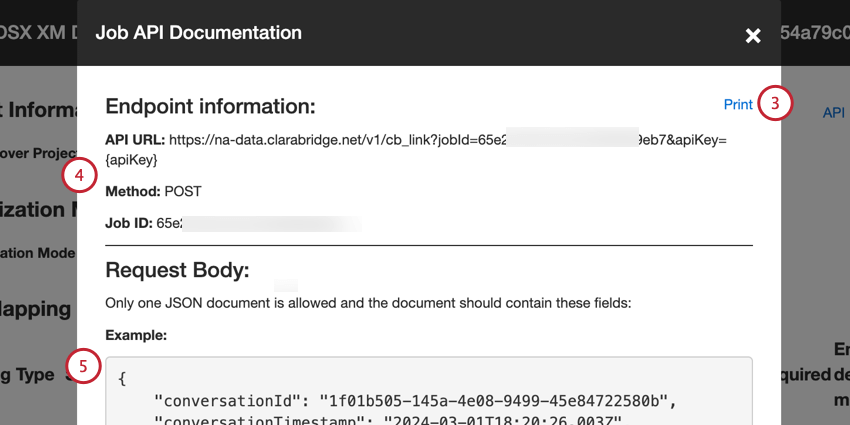
- Ihre Endpunktinformationen umfassen:
- API-URL: Die für die API-Anforderung verwendete URL.
- Methode: Verwenden Sie die POST-Methode, um Daten in XM Discover zu laden.
- Job-ID: Die ID des aktuell ausgewählten Jobs.
- Eine Beispiel-JSON-Payload ist im Abschnitt Request-Body enthalten. Eine API-Anforderung sollte nur ein Dokument enthalten und nur die Felder in der Beispiel-Payload enthalten.
- Im Abschnitt Antworten werden die möglichen Erfolgs- und Fehlerantworten der API-Anforderung aufgeführt.
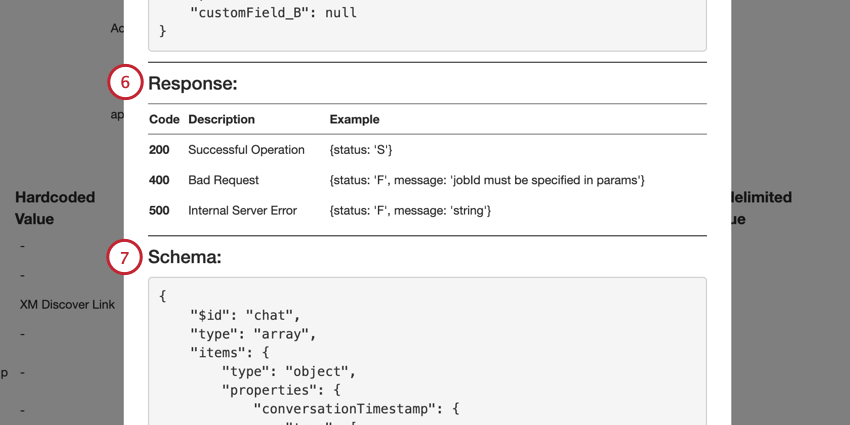
- Im Abschnitt Schema wird das Datenschema angezeigt. Erforderliche Felder befinden sich im erforderlichen Array.
Überwachen eines XM-Discover-Link-Jobs über API
Sie können den Status von XM Discover Link-Jobs überwachen, ohne sich bei XM Discover anzumelden, indem Sie den Status-API-Endpunkt aufrufen. Auf diese Weise können Sie den Status der letzten Jobausführung, Metriken für einen bestimmten Joblauf oder kumulierte Metriken für einen bestimmten Zeitraum abrufen.
Statusendpunktinformationen
Um den Statusendpunkt aufzurufen, benötigen Sie Folgendes:
- API-URL: https://na-data.clarabridge.net/v1/public/job/status/ <jobID> ?apiKey=<apiKey>
- <jobId> ist die ID des XM-Discover-Link-Auftrags, den Sie überwachen möchten.
- <apiKey> ist das API-Token.
- Typ: REST-HTTP verwenden
- HTTP-Methode: Verwenden Sie die GET-Methode, um Daten abzurufen.
Eingabeelemente
Die folgenden optionalen Eingabeelemente können verwendet werden, um zusätzliche Metriken zu Ihrem Job abzurufen:
- historicalRunId: Die ID der spezifischen Upload-Sitzung. Wenn dieses Element ausgelassen wird und kein Datumsbereich angegeben ist, gibt der API-Aufruf den Status des letzten Joblaufs zurück. Wenn dieses Element ausgelassen und ein Datumsbereich angegeben wird, gibt der API-Aufruf kumulierte Metriken für den angegebenen Zeitraum zurück.
- startDate: Legen Sie das Startdatum fest, ab dem Daten zurückgegeben werden sollen.
- endDate: Definieren Sie das Enddatum, um Daten basierend auf dem letzten Upload zurückzugeben. Wenn dieses Element ausgelassen und startDate angegeben wird, wird endDate automatisch auf das aktuelle Datum gesetzt.
Ausgabeelemente
Die folgenden Ausgabeelemente werden zurückgegeben, sofern Sie die erforderlichen Eingabeelemente eingegeben haben:
- job_status: Der Status des Jobs.
- job_failure_reason: Wenn der Job fehlgeschlagen ist, der Grund für den Fehler.
- run_metrics: Informationen zu den Dokumenten, die vom Job verarbeitet werden. Die folgenden Metriken sind enthalten:
- SUCCESSFULLY_CREATED: Die Anzahl der erfolgreich angelegten Dokumente.
- SUCCESSFULLY_UPDATED: Die Anzahl der erfolgreich aktualisierten Dokumente.
- SKIPPED_AS_DUPLICATES: Die Anzahl der Belege, die als Dubletten übersprungen wurden.
- FILTERED_OUT: Die Anzahl der Dokumente, die entweder von einem quellspezifischen Filter oder einem Konnektorfilter herausgefiltert wurden.
- BAD_RECORD: Die Anzahl der zur Verarbeitung übermittelten digitalen Interaktionen, die nicht mit dem Konversationsformat von Qualtrics übereinstimmen.
- SKIPPED_NO_ACTION: Die Anzahl der Belege, die als Nicht-Dubletten übersprungen wurden.
- FAILED_TO_LOAD: Die Anzahl der Dokumente, die nicht geladen werden konnten.
- INSGESAMT: Die Gesamtzahl der Dokumente, die während des Laufs dieses Jobs verarbeitet wurden.
Fehlermeldungen
Die folgende Fehlermeldung ist für den Status-API-Request möglich:
- 401 Nicht autorisiert: Authentifizierung fehlgeschlagen. Verwenden Sie einen anderen API-Schlüssel.
- 404 Nicht gefunden: Ein Auftrag mit der angegebenen ID ist nicht vorhanden. Verwenden Sie eine andere Job-ID.
Beispielanforderung
Nachfolgend finden Sie eine Beispielanfrage zum Abrufen des Status für einen Job:
curl --location --request GET 'https://na-data.clarabridge.net/v1/public/job/status/62da736987c9788b830918e0?apiKey=02e7a0e26b592632dd50f623e974fff6'
Beispielantwort
Nachfolgend finden Sie eine Beispielantwort für einen fehlgeschlagenen Job:
{
"job_status": "Failed",
"job_failure_reason": "{\"problem\":[{\"requestId":"RQ-MOB-f339aa58-71b6-4a1d-a67c-12b8d3439321","severity":"ERROR","description":"Length limit of 900 characters for attribute supportexenceresp" successfully }\" has been, length to11\, length is "
"
\,
length is 1043\
Payload-Beispiele
Dieser Abschnitt enthält 1 Beispiel-JSON-Payload für jeden unterstützten Typ strukturierter Daten (Feedback, Chat, Anruf).
- Klicken Sie hier, um die Feedback-Beispiel-Payload anzuzeigen.
curl --location --request POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4e583f9142ae48a1090a76' \
--header 'Content-Type: application/json' \
--data-raw '{
"dataSource": "Standard JSON",
"Row_ID": "id43682",
"store_number": "226,1,1,0,0",
"Adresse": "5916 W W Loop 282" "03.onTX""
store_number":"226,1,0,0",
"79ck": "5916 W Loop 289"289" Bleiben Sie auf dem Laufenden.",
"LTR": 10,
"state": "TX",
"Rewards_Member": "MyBestBuy"
}'
- Klicken Sie hier, um die Chat-Beispiel-Payload anzuzeigen.
curl --location --request POST 'https://na-data.clarabridge.net/v1/cb_link?apiKey=887fc11663c456f9f34844a8a8bdff64&jobId=5f4d77656afa99b0396ef959' \
--header 'Content-Type: application/json' \
--data-raw '{
"conversationId",
"conversationTimestamp": "2020-07-30T12:42:ParticipENT",
"content": {
"contentType": "Hello}isant]"
"CHAT" "Id:
",
Participent,
"timestamp": "2020-07-30T12:42:15.000Z",
"id": "3785201"
},
{
"ParticipantId": "2",
"text": "Hallo, bist du heute geöffnet?",
"timestamp": "2020-07-30T12:42:15.000Z",
"id": "3785202"
},
"
ParticipantId": "1",
"text": "We are open from 17:00 bis 23:00.",
"timestamp": "Particip20-3020-30T12:42:15.000Z",anta "37Z" "373" "id" "
" "
" "bestandteilnehmer-307-30T12:15.000Z",
entzw. "37Z" "id
" "id
" "
" Welchen Namen kann ich verwenden?",
"timestamp": "2020-07-30T12:42:15.000Z",
"id": "3785205"
}
}
,
"city": "Boston",
"source": "Facebook"
}'
- Klicken Sie hier, um die Beispiel-Payload des Aufrufs anzuzeigen.
curl --location --request POST 'https://na-data.clarabridge.net/v1/cb_link?}apiKey
=887fc11663c456f9f34844a8a8bdff64
&jobId=5f4e564d9242ae6e6308ff04' \
--header 'Content-Type: application/json' \
--data-raw '{
"conversationId",
"conversationTimestamp": "2020-07-30T10:15:45.000Z",
"content": {
"contentType" "contentType": "CALL isid" "" "CALL isid",
type
,
"start": 22000,
"end": 32000
},
{
"Participant_id": "2",
"text": "Hi, I have a some Questions.",
"start": 32000,
"end": 42000
}
],
"contentSegmentType": "TURN"
},
"city" "city": "Boston",