
Text iQ Functionality
What's on this page
About Text iQ Functionality
Text iQ is Qualtrics’ powerful text analysis tool. Text iQ allows you to assign topics to feedback you’ve received, perform sentiment analysis, report out on your results with dynamic widgets, and more!
This page discusses spellcheck and lemmatization capabilities of Text iQ, what options are available to Basic vs. Advanced clients, and how to navigate the Text iQ interface.
Qtip: To access Text iQ, your account must have the Edit Survey Responses permission enabled.
Attention: Some ad-blockers interfere with Text iQ’s ability to load. If you are having trouble loading Text iQ, make sure your ad blockers are turned off.
Attention: Text iQ in CX Dashboards is completely separate from Text iQ in surveys. While this support page will cover general Text iQ functionality, we recommend that you also read Text iQ in CX Dashboards if you are performing text analysis in a dashboard.
Basic vs. Advanced Text
This section explains the differences in the features accessible to Basic versus Advanced text clients.
Qtip: Both Basic and Advanced Text iQ supports responses in English, Spanish, German, French, Italian, Polish, Russian, Swedish, Portuguese, Japanese, Dutch, Thai, Simplified Chinese, and Korean. Advanced analyses may support different languages. See Recommended Topics and Sentiment Analysis for the languages supported by these features.
Qtip: If you don’t currently have Advanced Text iQ but would like to gain access, feel free to reach out to your Account Executive.
| Basic | Advanced | |
|---|---|---|
| Response Limit | 20,000 Responses per survey | Unlimited Responses per survey |
| Summary Mode | No | Yes |
| Edit Mode | Yes | Yes |
| Search Responses | Yes | Yes |
| Create / Edit Topics | Yes | Yes |
| Hierarchical Topics | Yes | Yes |
| Widgets | No | Yes |
| Recommended Topics | No | Yes |
| Sentiment Analysis | No | Yes |
| Query Builder | No | Yes |
| Translate Comments | No | Yes |
| Text-iQ Powered Survey Flows | No | Yes |
| Additional Enrichments | No | Yes |
Qtip: If a project has been collaborated with your account, your Text iQ access may be further restricted. For more information, please see Collaboration Permissions.
Uploading Data to Text iQ
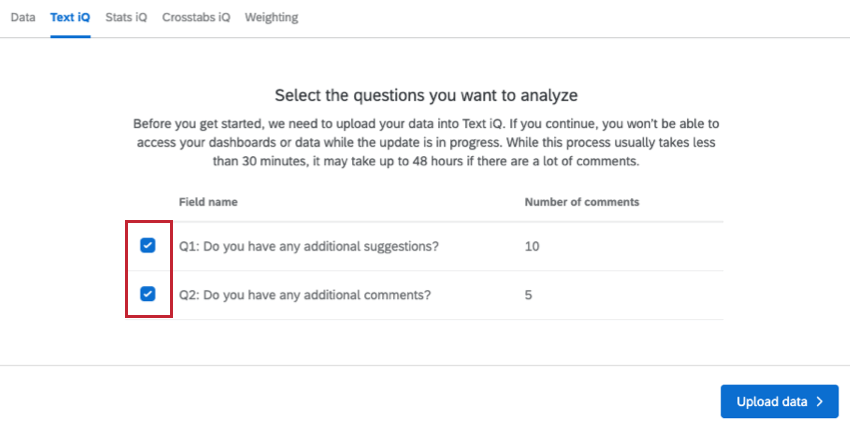
The first time you visit Text iQ in a survey, you have to upload your data. This process must be repeated for each survey you create, even if you have previously set up Text iQ in a different survey.
Use the checkboxes to select which open-ended text fields you would like to upload to Text iQ. Only questions or other compatible fields, such as a Text Variable Type Embedded Data field, will appear here.
{kind=link}
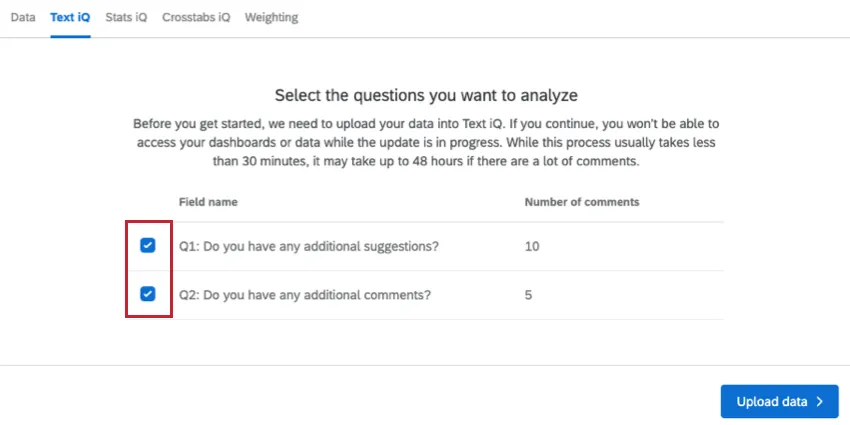
When you have finished selecting your fields, click Upload data. While the upload is in progress you won’t be able to access your dashboards or data.
Qtip: Once you choose a question to upload, this question cannot be removed. Uploading data will also add an extra “Topic” column to your Data & Analysis table.
Qtip: While this process usually takes less than 30 minutes, it may take up to 48 hours if there are a lot of comments.
Additional text fields can also be added after your data is first uploaded to Text iQ. Use the Field dropdown to add fields to Text iQ.
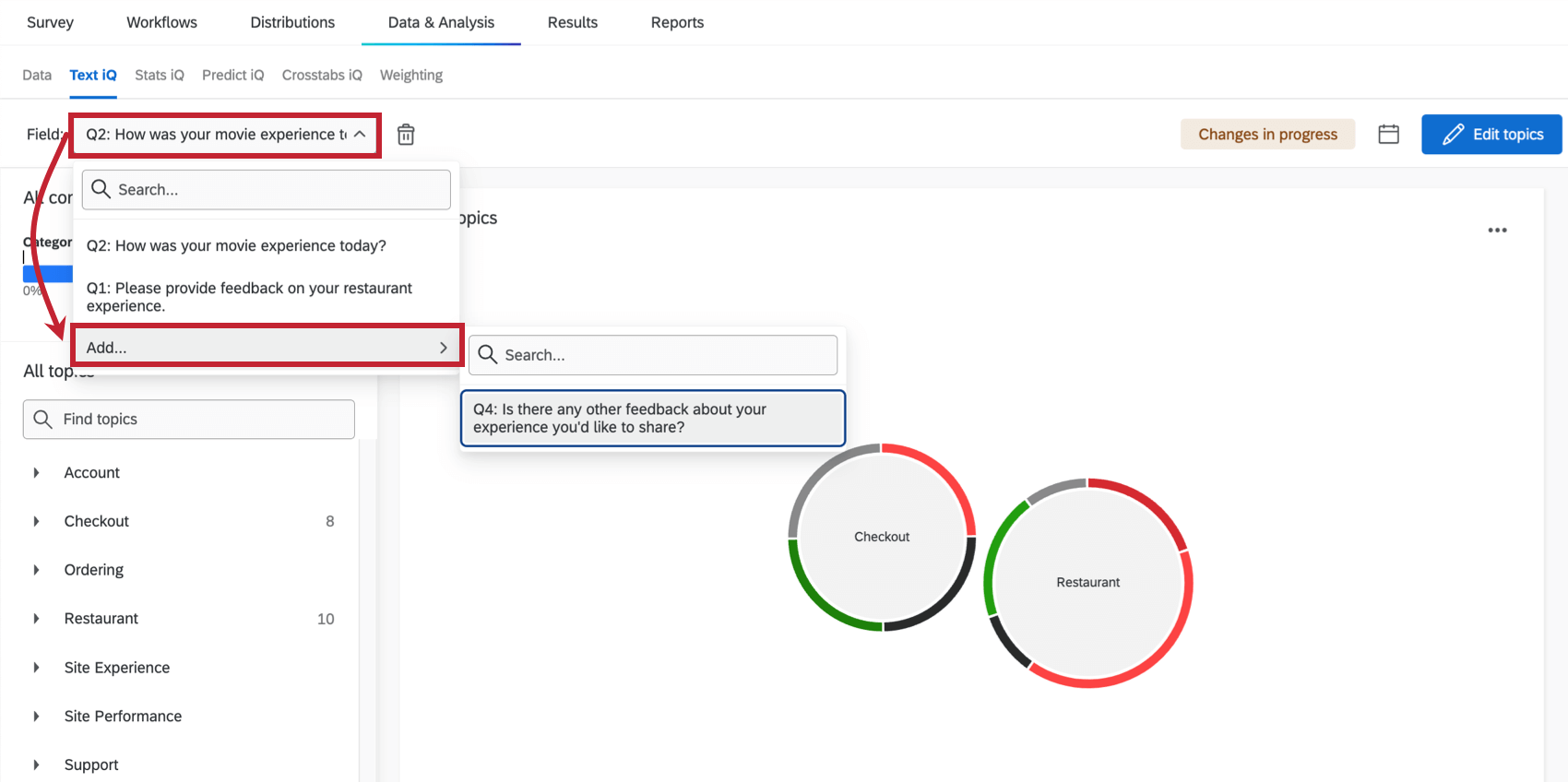
Qtip: Adding new fields will cause your dataset to update, making it temporarily unavailable. See Dataset Rebuilds Necessary for more information.
Qtip: You can remove fields from Text iQ as needed.
Qtip: There is no minimum number of responses required to use Text iQ.
Adding New Responses
New responses will be automatically added to Text iQ as they are collected, although it may take some time before they appear in Data & Analysis or in Text iQ.
Editing Mode and Applying Changes
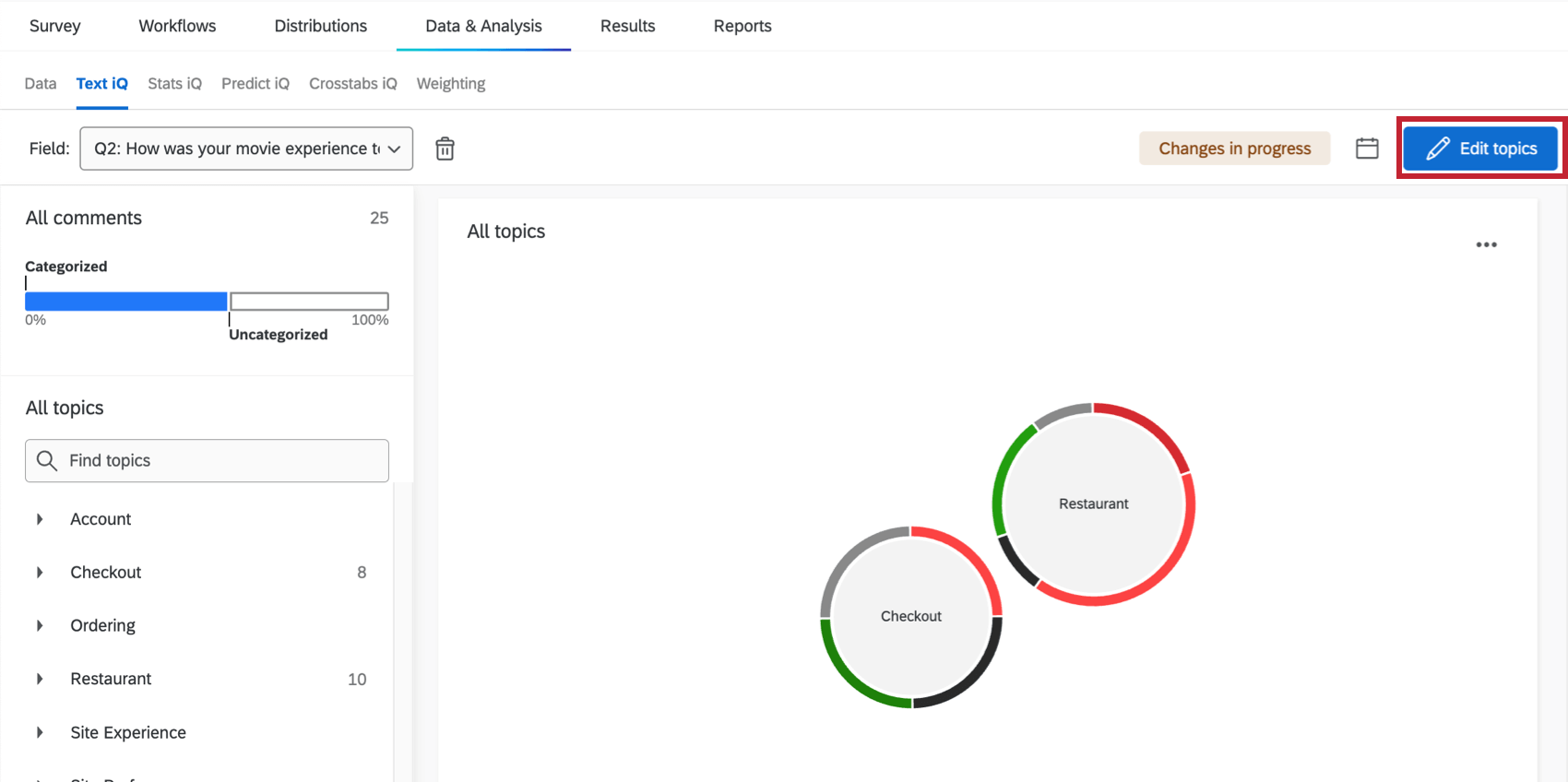
Before you can start adding topics and widgets, you have to put Text iQ in editing mode. You can only see the edit button to enter edit mode after you’ve already created at least one topic. To enter editing mode, click Edit topics.
{kind=link}
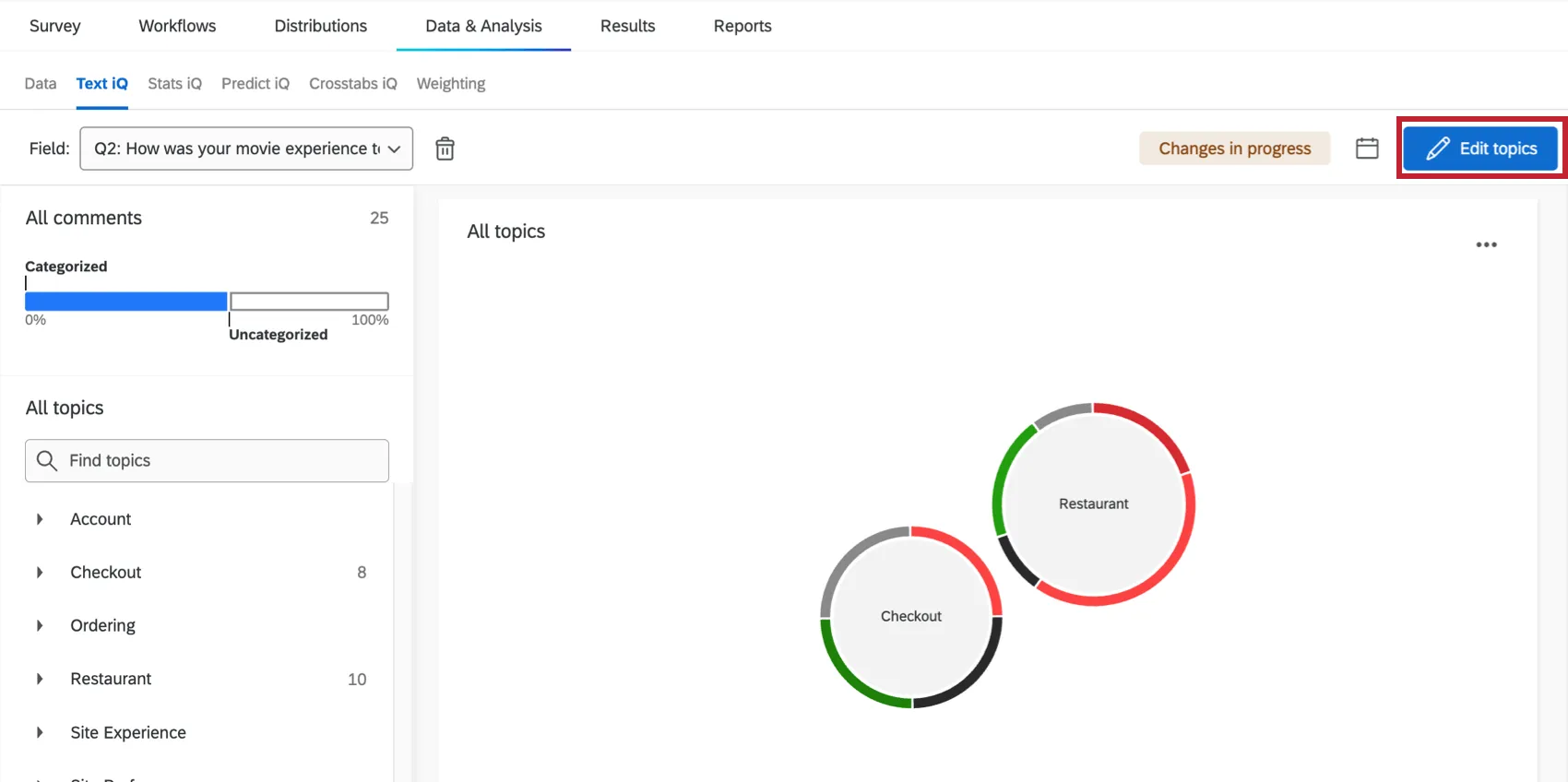
Once this button changes to “Return to summary,” you are ready to start editing!
{kind=link}
Qtip: You may notice that you do not have the option to switch between editing and summary mode. Basic text clients will always be in editing mode.
Saving Your Edits
There are a lot of features in Text iQ, and therefore a lot of edits you can make. You can change how feedback is tagged by topic, your sentiments, and more. However, you don’t want resulting changes to take place immediately, since waiting for each change to implement can be time consuming.
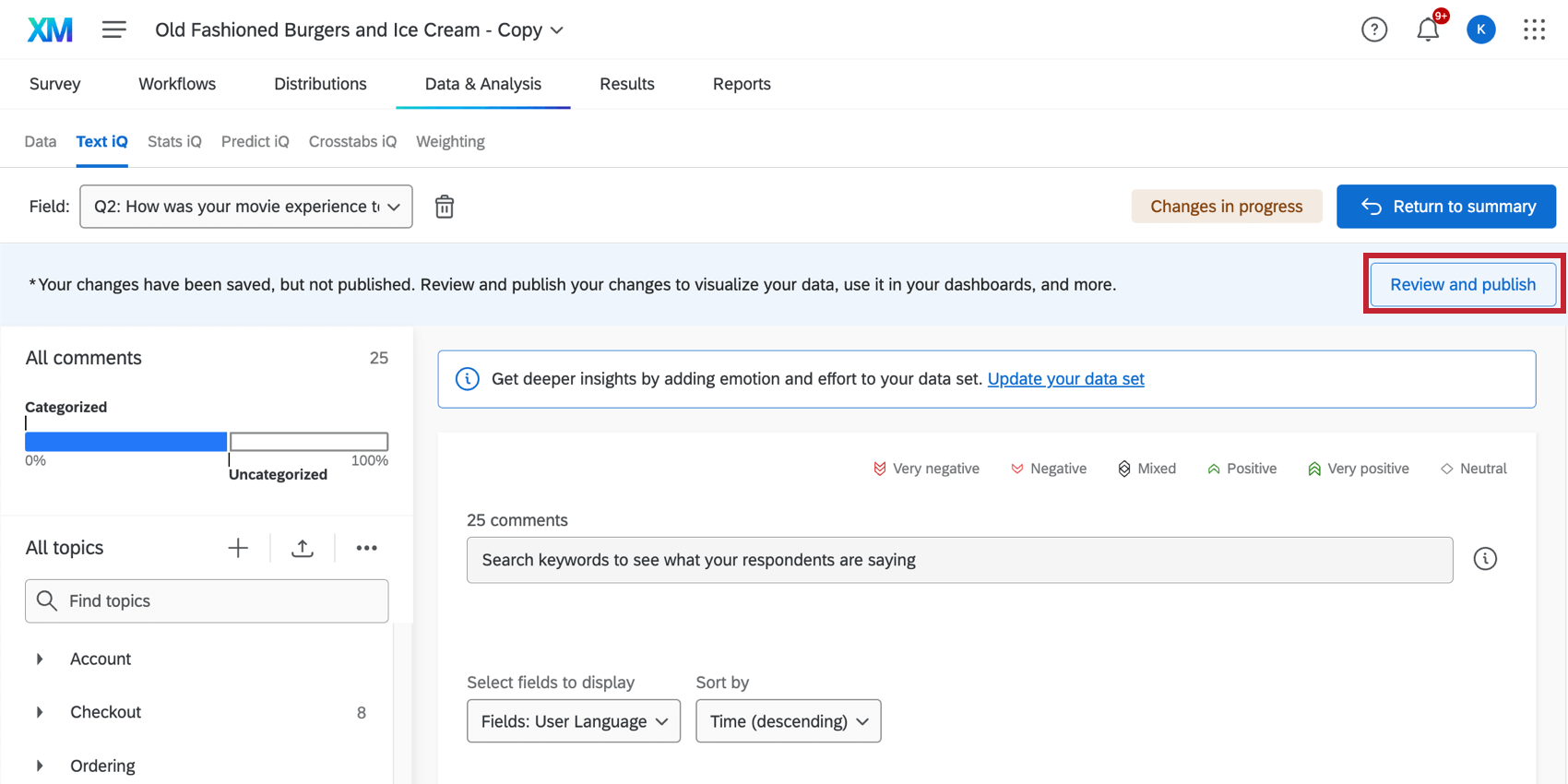
If you’ve made edits, a banner will appear explaining that your changes have been saved, but not yet applied to the dataset. This means your changes aren’t reflected in any of your reports or dashboards yet.
After you’re done editing, click on the Review and publish button in the upper-right.
{kind=link}
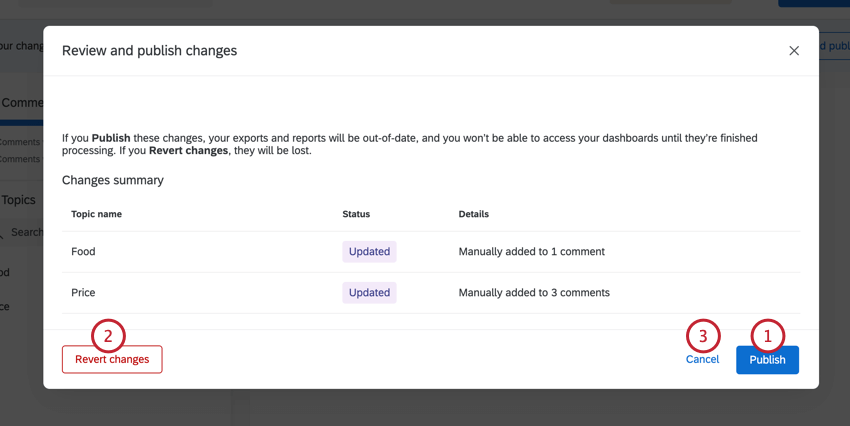
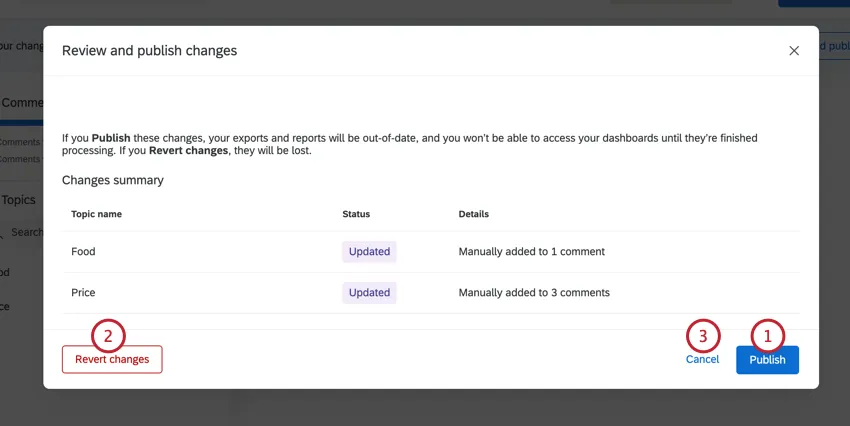
Before your changes are applied, a summary of your proposed changes will appear. You can review these before deciding to either:
{kind=link}
Once you save, Qualtrics will take care of the rest. You are free to use other parts of the site while your changes are processed.
Attention: When publishing text projects, it is normal to experience latency anywhere from 30 minutes to 48 hours from publishing to when the changes are displayed.
Navigating Text iQ
Let’s outline all the components of Text iQ.
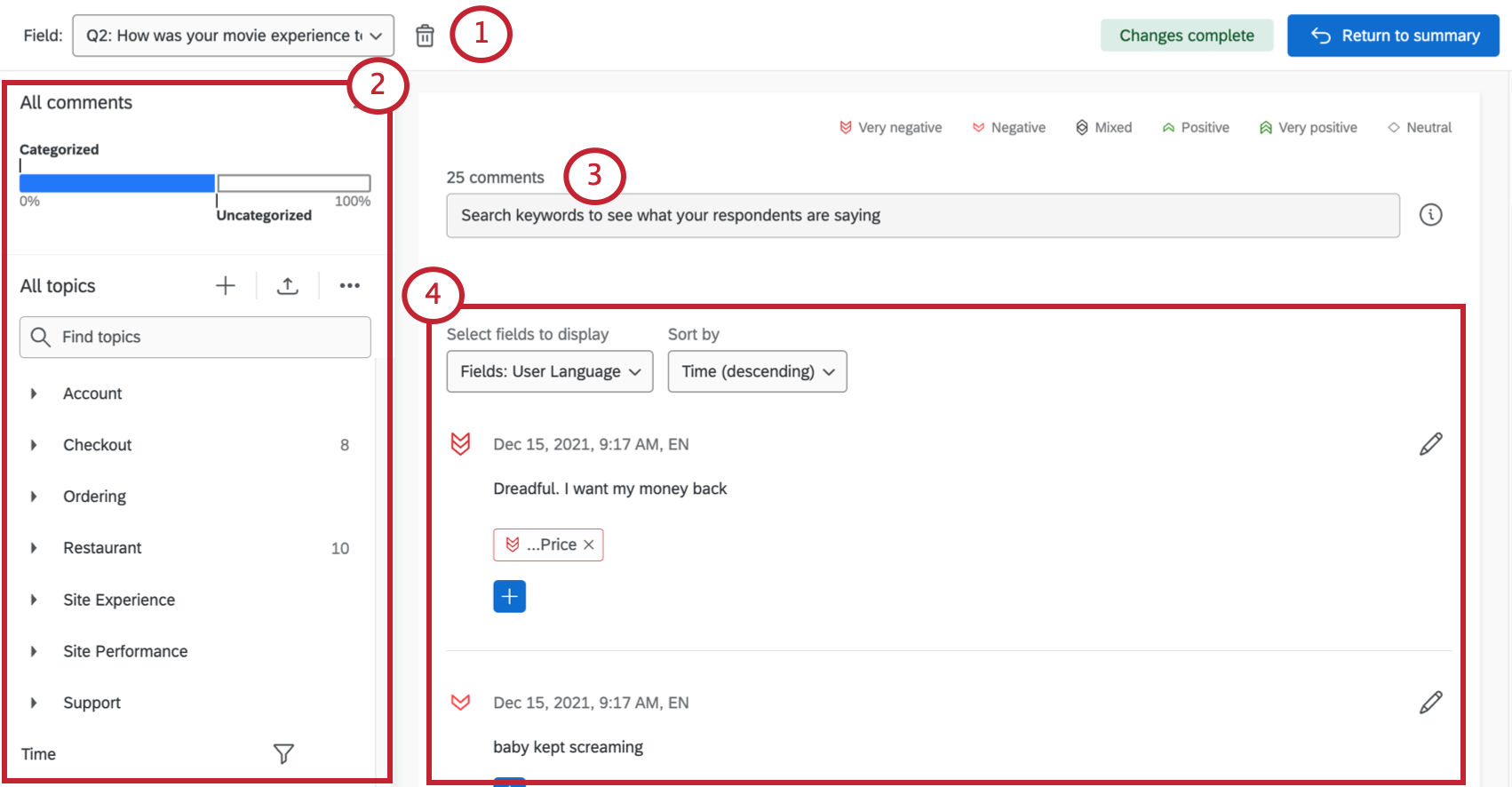
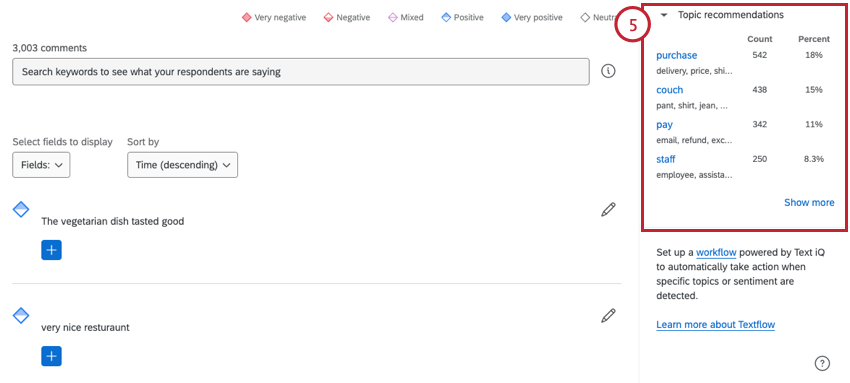
Qtip: In editing mode, you can use the Sort by field to sort comments by ascending or descending time. The time is based on the survey response’s recorded date.
Viewing Responses in Text iQ
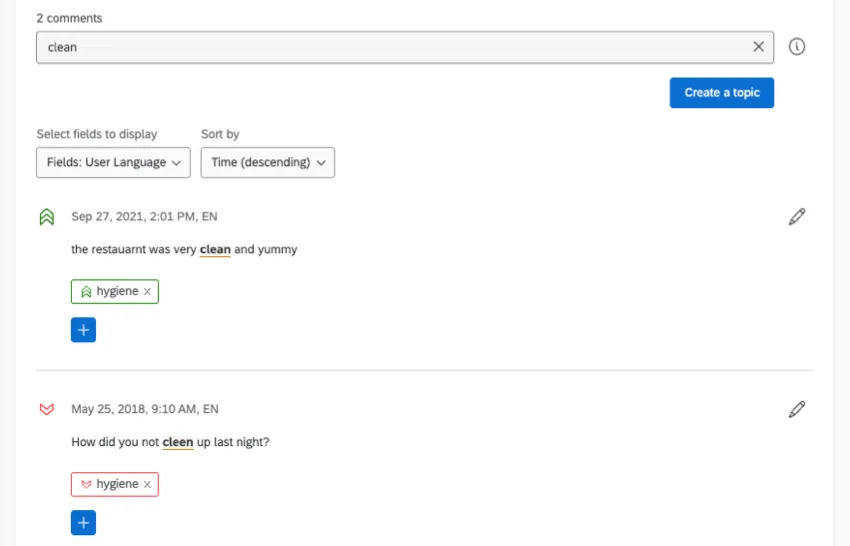
Each response comes with a sentiment score (the number in the bubble), the response itself, and a list of the topics it’s been tagged with.
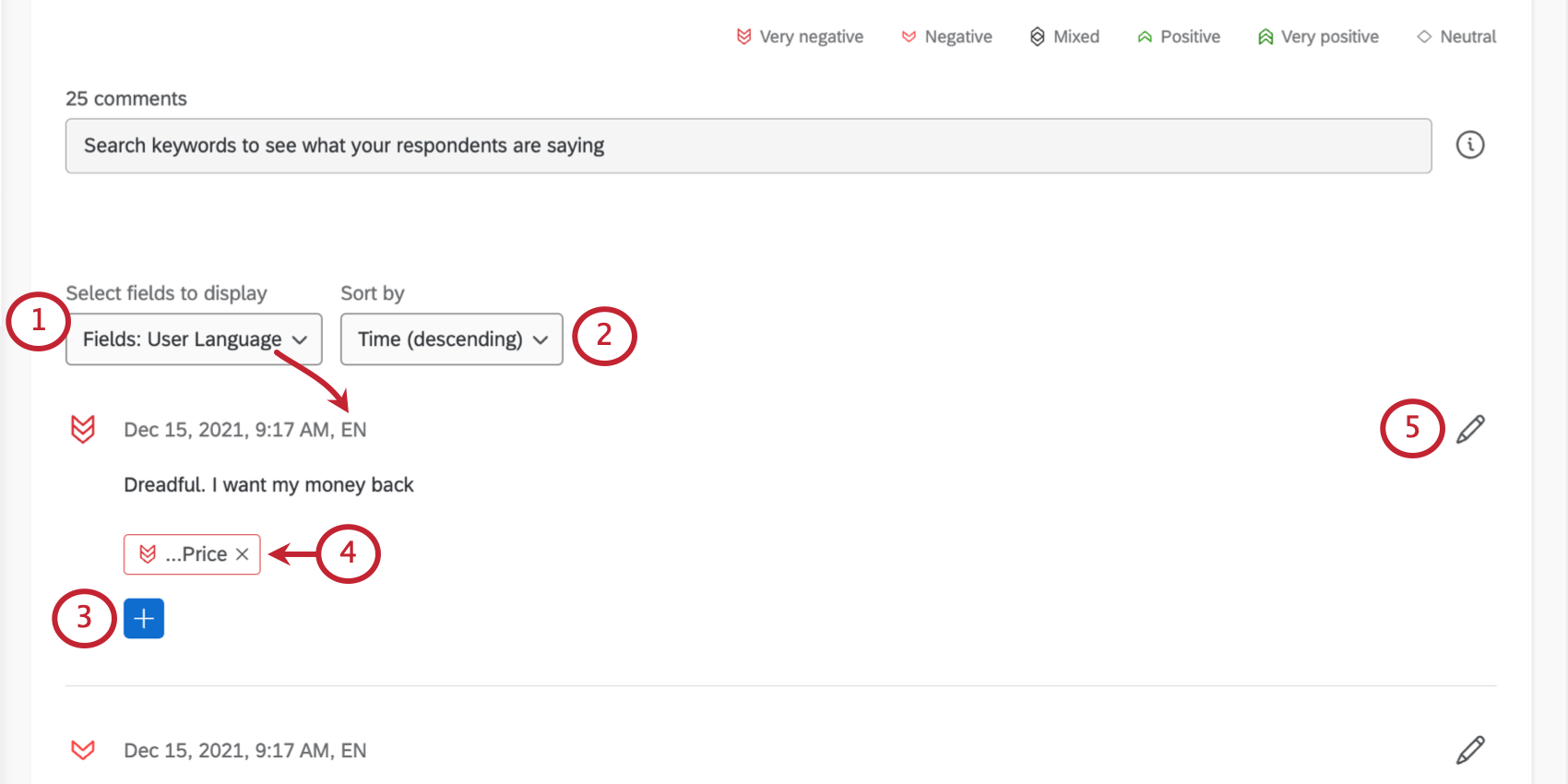{kind=link}
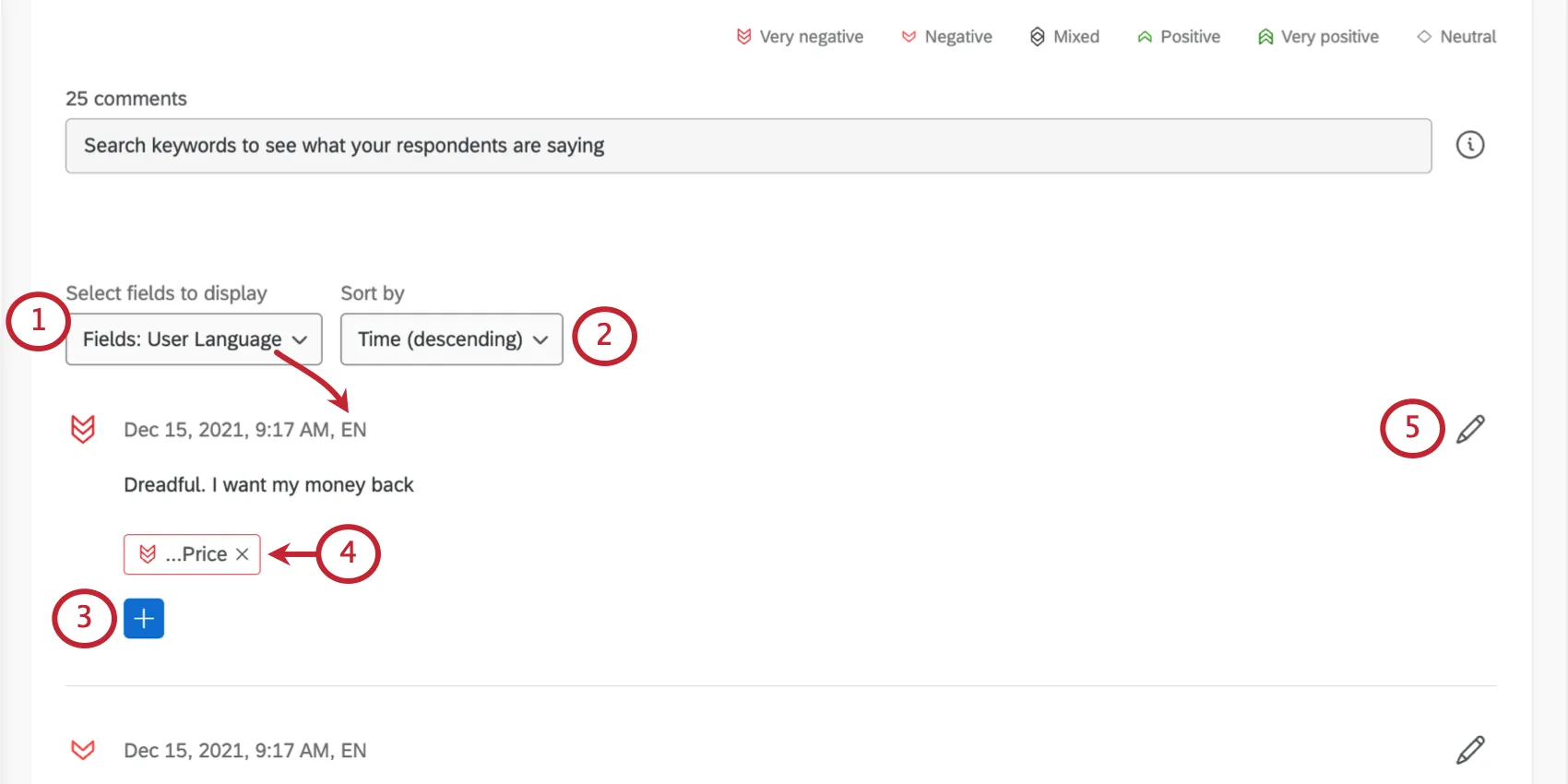
Qtip: You cannot add contact information here unless it’s been added as embedded data.
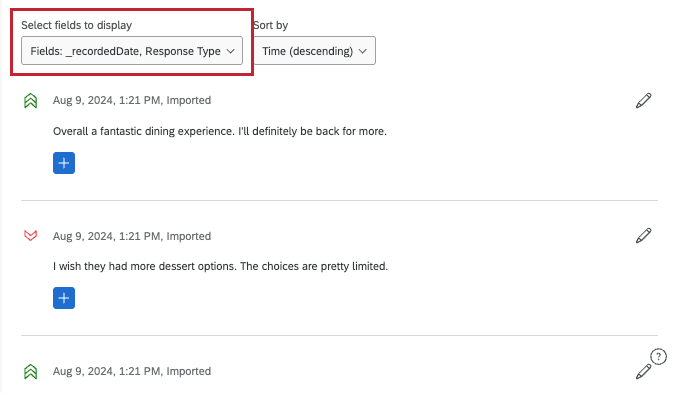
Selecting Fields to Display
Each entry in Text iQ shows you an individual comment and the sentiment and topics assigned to it. However, you can add more fields to display along the top of your comments, helping you gather insight on your data.
Enter editing mode, then use Select fields to display to automatically add information to each comment. You can select multiple fields.
{kind=link}
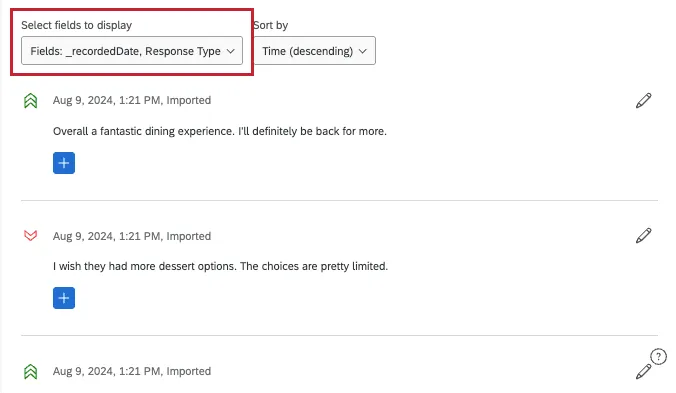
The fields you can select include:
- Survey Metadata: Default information collected in the survey, such as the date the response was recorded, progress, and duration. If you’re not sure what a survey metadata field means, check out Respondent Information.
- Embedded Data: Include embedded data from your survey. This includes both custom data you added to responses, and fields different features add to the dataset, like Expert Review fields and Text iQ enrichments. Only text set fields appear in this menu (non-numeric fields with single-select values).
Lemmatization
Lemmatization is the process of breaking words down in order to capture the base roots of the word, then identifying all derivatives and conjugations for that word in order to provide more robust results. For the Text section, lemmatization is used to ensure that your responses are tagged correctly without you having to use complicated query searches.
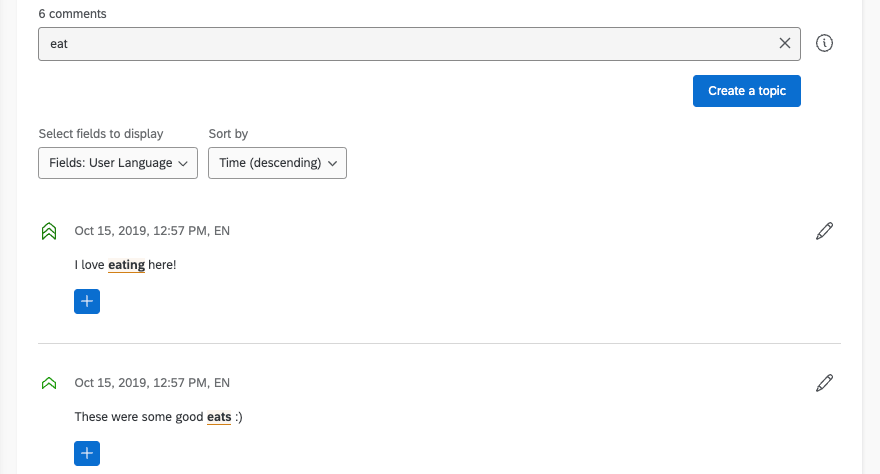
As an example, let’s consider that we want to capture all the comments from our restaurant’s NPS® survey that mention eating and food.
In other keyword search tools, you might have to develop some long query string that includes the various iterations of eat (eating, eats, etc). However, with Text, the system uses lemmatization to break all those words down to the core base word, “eat,” and then tags responses appropriately.
{kind=link}
Spell Check
The Text section also includes a basic spell checking system to ensure that all your responses get tagged correctly, even if the respondent has misspelled or incorrectly capitalized a word.
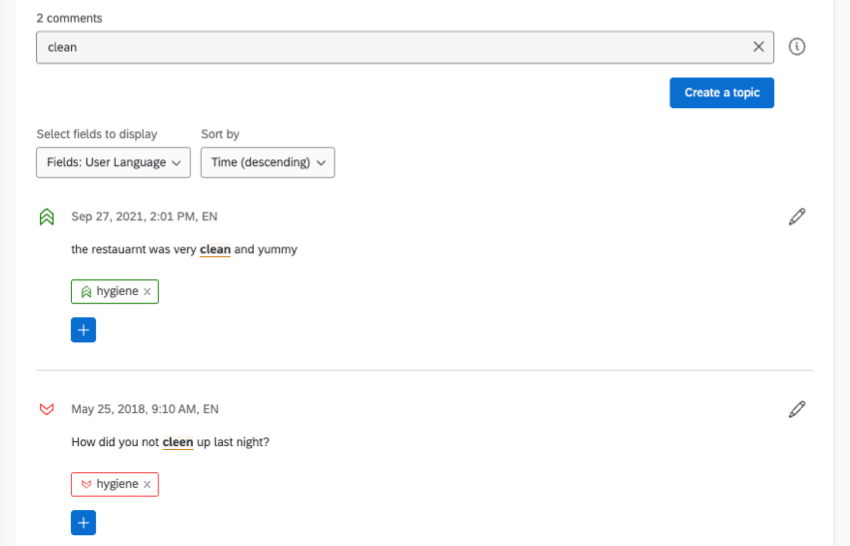
For example, let’s look at our restaurant again. If we want a topic about cleanliness, you can bet that there will be a few misspelled words. However, the Text spell check will still capture the misspelled words and tag them, so you don’t have to worry about any responses falling through the cracks.
{kind=link}
Dataset Rebuilds Necessary
There may be times that Text iQ asks you to update the dataset. A dataset update is different than the usual changes you make and apply in the Text iQ platform. The big difference is that dataset updates cause your dataset to reindex, which results in the temporary inability to access not only Text iQ itself, but the dataset the text responses come from. If you are using Text iQ in a survey, that means the survey’s Data & Analysis tab will be unusable until the update ends. If you are using Text iQ in a CX dashboard or employee engagement project, the dashboards will not display data until the update ends.
For most users the update will take less than 30 minutes, but for datasets that include lots of responses, this process can take up to 48 hours. We provide advanced warning so you can navigate away and delay the update if desired, or follow the directions to start the dataset update.
Request to Update Dataset
{kind=link}
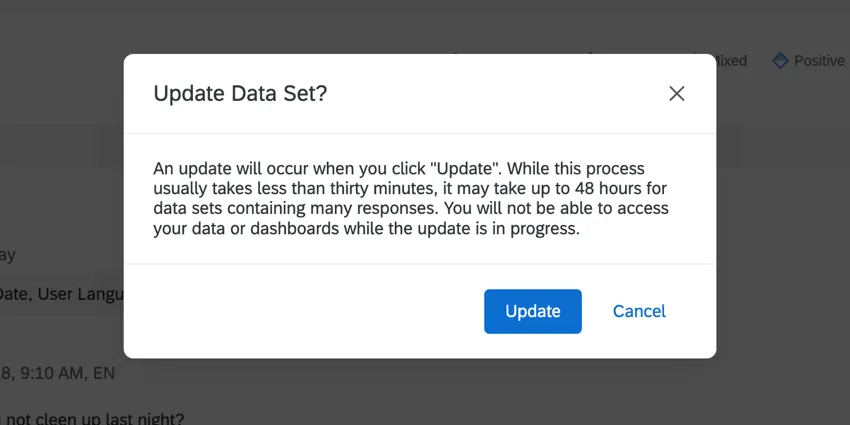
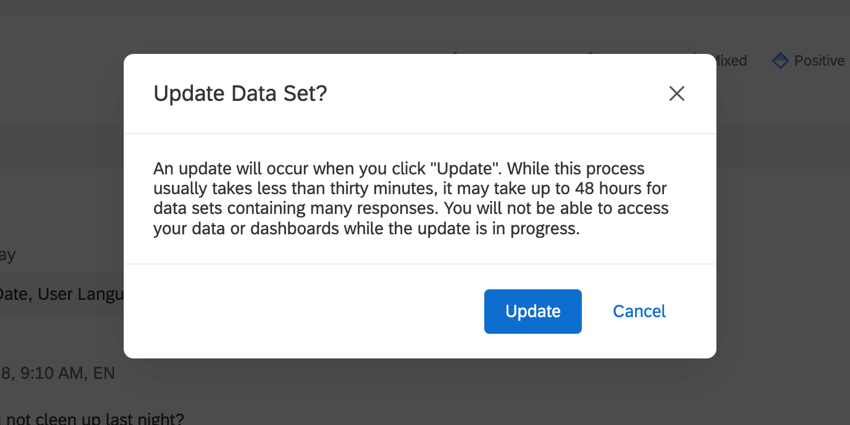
Text iQ may give you an “Update Data Set?” window if you’re visiting a question for the first time in Text iQ. This is a question (or another compatible field, such as a Text Variable Type Embedded Data field) you’ve never analyzed in Text iQ, even if you’ve used Text iQ on other questions in the same survey / dashboard before.
This window may also appear if there is an issue with the way data was mapped in a dashboard – for example, if you changed a Field Type – or if you make a change that utilizes analysis features you weren’t using previously. An example of using new analysis features includes adding parent topics, or topic-level sentiments.
To defer the update, click Cancel. To start the update, click Update.
Warning When You Publish Changes
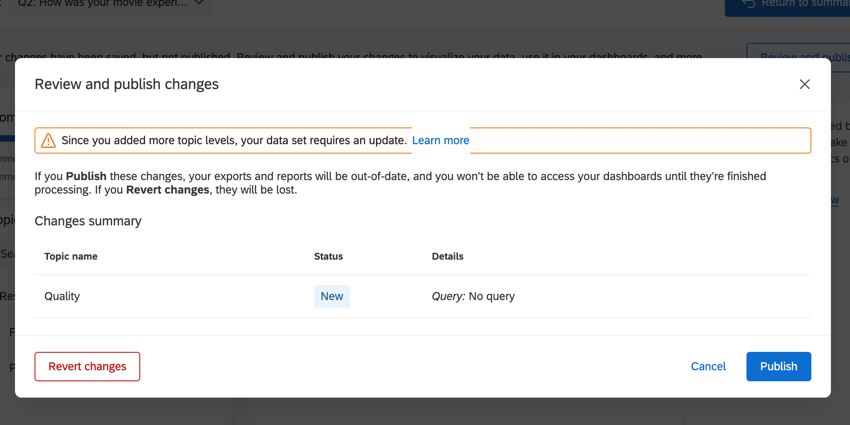{kind=link}
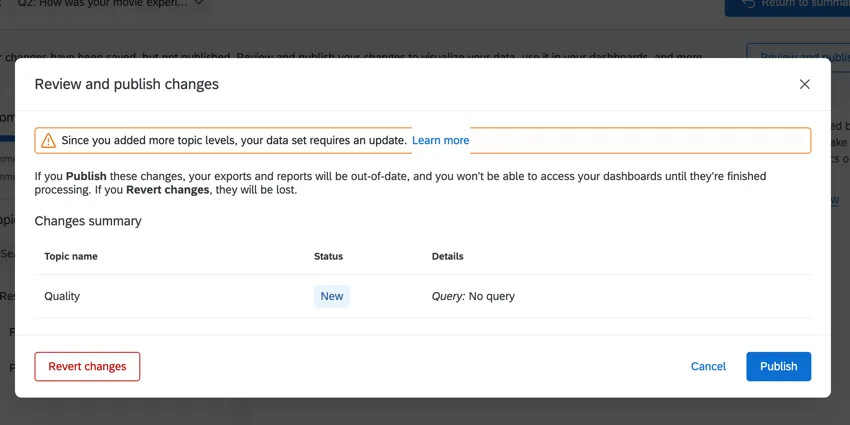
When you go to publish your changes, you may also get a warning that pushing changes will require a dataset update. This likely happened because you were editing topic hierarchies. For example, nesting topics under a parent topic, removing a topic from a parent, or creating a new parent topic.
Click Publish to push the update. Click Cancel to return to Text iQ and make additional changes before you start the update.
Warning: You will lose all the changes you made if you click Revert changes!
Deleting Text Analysis
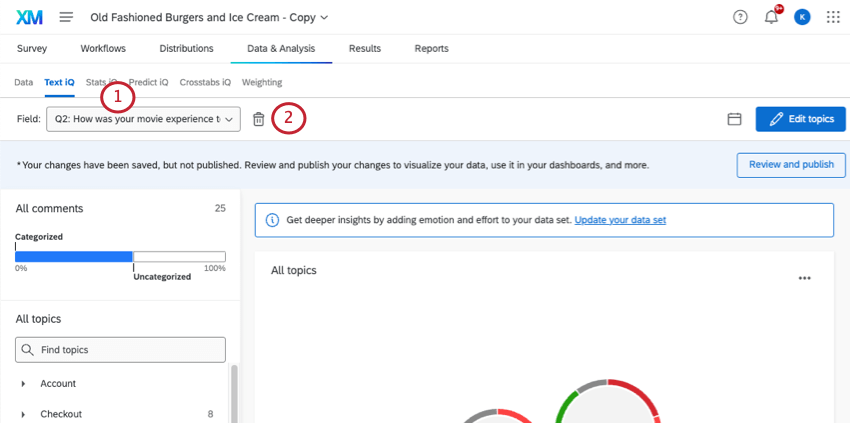
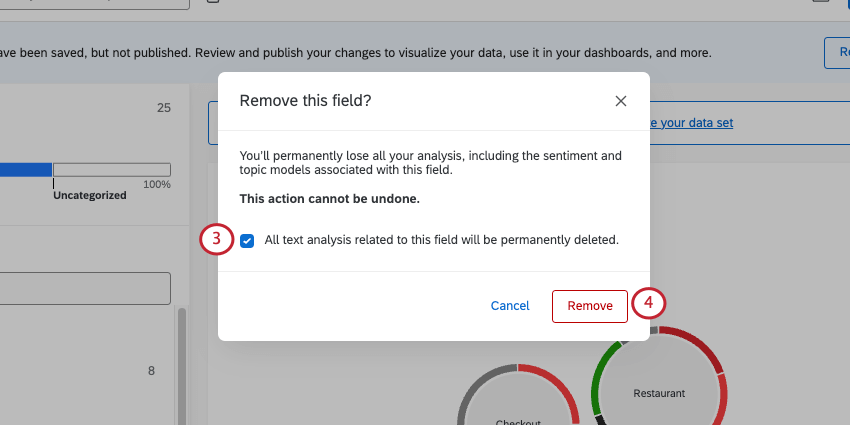
Once you’ve started to analyze a field in Text iQ, you can delete this field from Text iQ. This functionality lets you remove fields you didn’t intend to analyze, or that you may want to start from scratch with.
Fields deleted from Text iQ are not deleted from the Data tab. However, all Text iQ analyzed fields, such as sentiment and topics, will be.
Attention: Once a field is deleted from Text iQ, any text analysis you performed cannot be retrieved. Do not remove a field from Text iQ unless you are sure you want to remove all of your text analysis for it, including the sentiment and topic models.
FAQs
I don't have the tab described on this page! What do I do?
I don't have the tab described on this page! What do I do?
That's great! Thank you for your feedback!
Thank you for your feedback!